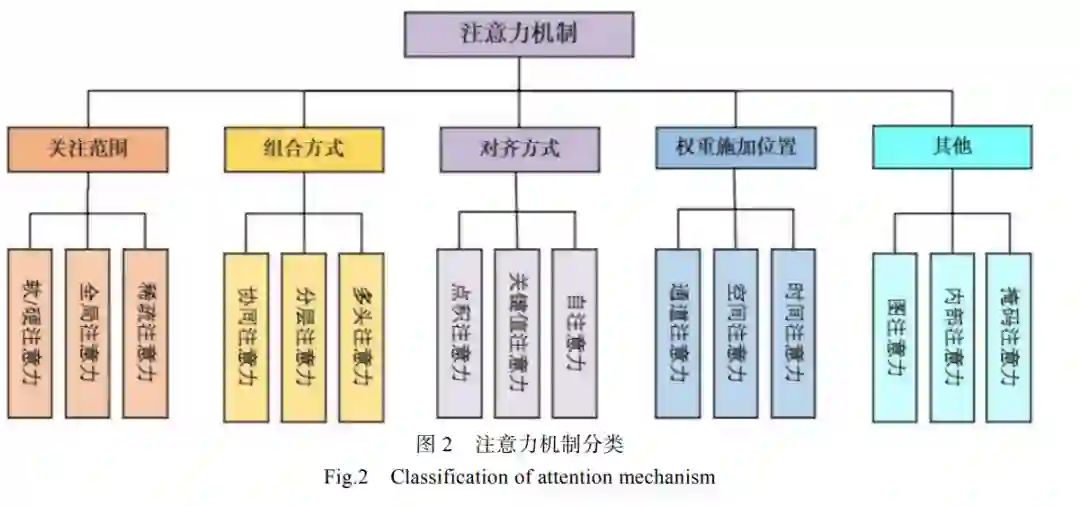
摘要: 近年来,强化学习与注意力机制的结合在算法研究领域备受瞩目。在强化学习算法中,注意力机制的应用在提高算法性能方面发挥了重要作用。本文重点聚焦于注意力机制在深度强化学习中的发展,审视了其在多智能体强化学习领域的应用,并对相关研究成果进行调研。首先介绍了注意力机制和强化学习的研究背景与发展历程,并调研了该领域中的相关实验平台;然后,回顾了强化学习与注意力机制的经典算法,并从不同角度对注意力机制进行分类;接着,对注意力机制在强化学习领域的应用进行了梳理,根据三种任务类型(完全合作型、完全竞争型和混合合作竞争型)进行分类分析,重点关注了多智能体领域的应用情况;最后总结了注意力机制对强化学习算法的改进作用,并展望了该领域所面临的挑战和未来的研究前景。本文的工作有助于研究人员更深入地探索该领域,有助于进一步推动强化学习与注意力机制在实际项目中取得更加广泛和深远的应用,为未来的研究提供了一定的指导作用。 随着人工智能技术的不断发展,强化学习 (Reinforcement Learning, RL)和注意力机制的结 合在多机器人控制领域受到了越来越多的关注。RL 是机器学习的一个分支,专注于处理序列决策问题, 具有良好的鲁棒性能和能够更好地适应环境的优 点[1]。在实际 RL 应用中,智能体接收到的信息复 杂且繁多,并且 RL 算法的可解释性较低。为了解 决这些难题,研究人员在 RL 中引入了注意力机制。 随着机器学习的发展和计算机算力的提升, RL 领域、注意力机制领域以及二者相结合的应用 正受到越来越多的关注。在过去几十年中,研究人 员们提出了多种与其相关的算法,充分发挥了 RL 的决策能力和注意力机制的信息处理能力,以实现 多个智能体之间的最优决策。1989 年,Watkins 和 Dayan 将 Bellman 方程、Markov 决策过程等最优控 制理论与时间差学习相结合,创造了 Q-learning 算 法。随后,Q-learning 被广泛应用于解决各种实际 问题。注意力机制最早于 2014 年被提出,由 Google Mind 团队的研究人员[2]引入了一种基于 RNN 的注 意力模型,名为视觉注意的循环模型,旨在解决视 觉任务中的对象识别和图像分类等问题。随着智能 体数量的增加,各个智能体之间需要处理和沟通以 做出决策的信息也在显著增加,这会导致有用信号 淹没在背景噪声中。为了应对这一问题,研究人员 [3]提出了一种基于注意力机制的多智能体强化学 习(Multi-Agent Reinforcement Learning, MARL)算 法——多重注意力演员-评论家算法(Multiple Attention Actor-Critic with Attention, MAAC-A )。 MAAC-A 通过一个集中的评论家和多个分散的演 员来学习多智能体系统(Multi-Agent System, MAS)。 为了克服传统价值函数方法和 PG 方法在多智能体 问题上的限制,MAAC-A 借鉴了多智能体深度确定 性策略梯度方法(Multi-Agent Deep Deterministic Policy Gradient, MADDPG),该方法运用注意力机 制关注不同智能体之间的交互,从而提高学习效率 和性能。随后,2021 年,研究者[4]提出了一种基于 自关注机制的深度循环 Q 学双引擎谣言检测模型, 结合自注意力机制和 RL,可以更早地排除不必要 的信息,进而提高准确率。由于其处理大量信息的能力,注意力机制在RL 领域引起了广泛关注。OpenAI、DeepMind和Google Brain 等团队是该领域的领导者,发表了多种具有里程碑意义的方案,对RL研究产生了深远的影响。此外,许多学者和团队的努力推动了RL中注意力机制的迅速发展,为未来解决各种RL问题奠定了基础。近年来,在中国、美国和欧洲出现了更多的 RL 工作室,反映了该领域的快速发展趋势。目前,关于 RL 的综述性论文大约有400篇。然而,仅有大约40 篇综述性论文探讨了其在多智能体领域的应用。这些综述从不同的角度出发,包括 RL 协作([5,6]引用)、竞争[7]、混合[8]等不同分类,以及从无人机无人驾驶飞行器(UnmannedAerial Vehicles , UAV)领域[9,10]、通信[11]、交通信号[12]、微电网[13]、资源分配[14,15] 、运动控制[16]等不同领域的应用,对RL 以及MARL算法进行了深入讲述。作为人工智能发展前沿的一部分,RL与注意力机制的结合已引起许多国家的重视。尽管有关于和注意力机制的综述已有许多,但专注于多智能体领域中注意力机制与RL 结合应用的综述尚未出现。因此,本文旨在填补这一研究空白,重点关注2014年一月至 2023 年十月的RL 与注意力机制结合在多智能体领域的研究成果,并进行了全面总结。本文的主要贡献如下:(1)回顾了深度学习中注意力机制的经典算法,根据不同的角度对注意力机制进行分类;(2)首次系统介绍了近年来RL 中的注意力机制算法的结合情况以及研究进展,是该领域的第一次综述; (3)对注意力机制在MARL 领域的应用进行了梳理,关注并展望了该领域所面临的挑战和未来的研究前景。我们的工作有助于研究人员更好地深入研究该领域。 本文主要探讨了注意力机制在DRL中的发展和应用,旨在为后续基于RL 的注意力机制应用提供概念理解和理论支持。