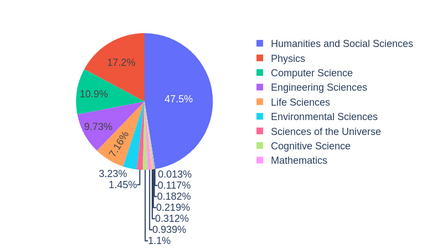
Text Summarization is a popular task and an active area of research for the Natural Language Processing community. By definition, it requires to account for long input texts, a characteristic which poses computational challenges for neural models. Moreover, real-world documents come in a variety of complex, visually-rich, layouts. This information is of great relevance, whether to highlight salient content or to encode long-range interactions between textual passages. Yet, all publicly available summarization datasets only provide plain text content. To facilitate research on how to exploit visual/layout information to better capture long-range dependencies in summarization models, we present LoRaLay, a collection of datasets for long-range summarization with accompanying visual/layout information. We extend existing and popular English datasets (arXiv and PubMed) with layout information and propose four novel datasets -- consistently built from scholar resources -- covering French, Spanish, Portuguese, and Korean languages. Further, we propose new baselines merging layout-aware and long-range models -- two orthogonal approaches -- and obtain state-of-the-art results, showing the importance of combining both lines of research.
翻译:文本摘要是自然语言处理社区最受欢迎的任务和积极的研究领域。 根据定义,它要求说明长期输入文本,这是神经模型的计算挑战。此外,真实世界文件来自各种复杂、富有视觉的布局。这种信息具有极大的相关性,无论是突出突出的内容,还是将文本段落之间的长距离互动编码。然而,所有公开提供的汇总数据集都只提供纯文本内容。为了便利研究如何利用视觉/外延信息更好地捕捉总结模型的长距离依赖性,我们提出LoRaLay,这是一套长距离汇总数据集,同时附有视觉/外延信息。我们扩展现有和流行的英国数据集(arXiv和PubMed),提供布局信息,并提议四个新数据集 -- -- 始终以学术资源为基础 -- -- 涵盖法文、西班牙文、葡萄牙文和韩文。此外,我们提议新的基线,将布局和长距离模型 -- -- 两种或深层次方法 -- -- -- 合并成一线 -- -- 并获得状态研究成果的重要性。