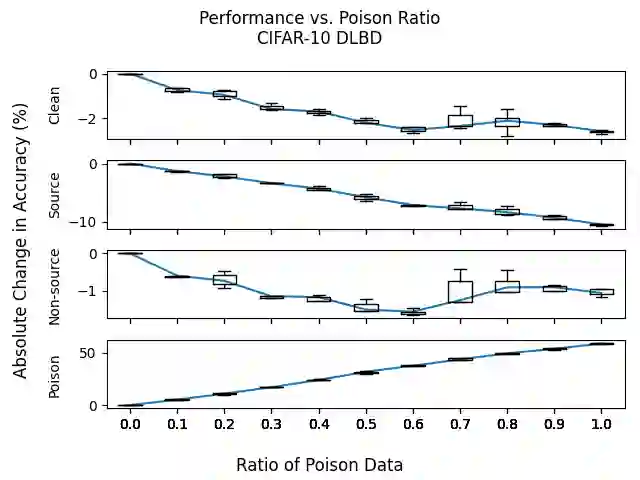
As deep learning datasets grow larger and less curated, backdoor data poisoning attacks, which inject malicious poisoned data into the training dataset, have drawn increasing attention in both academia and industry. We identify an incompatibility property of the interaction of clean and poisoned data with the training algorithm, specifically that including poisoned data in the training dataset does not improve model accuracy on clean data and vice-versa. Leveraging this property, we develop an algorithm that iteratively refines subsets of the poisoned dataset to obtain subsets that concentrate around either clean or poisoned data. The result is a partition of the original dataset into disjoint subsets, for each of which we train a corresponding model. A voting algorithm over these models identifies the clean data within the larger poisoned dataset. We empirically evaluate our approach and technique for image classification tasks over the GTSRB and CIFAR-10 datasets. The experimental results show that prior dirty-label and clean-label backdoor attacks in the literature produce poisoned datasets that exhibit behavior consistent with the incompatibility property. The results also show that our defense reduces the attack success rate below 1% on 134 out of 165 scenarios in this setting, with only a 2% drop in clean accuracy on CIFAR-10 (and negligible impact on GTSRB).
翻译:随着深层学习数据集的扩大和缩小范围,将恶意有毒数据输入培训数据集的后门数据中毒袭击日益引起学术界和行业的注意。我们发现清洁和有毒数据与培训算法相互作用的不相容性,特别是将有毒数据纳入培训数据集并不能提高清洁数据和反向数据的模型准确性。利用这一属性,我们开发了一种对有毒数据集子集进行迭接精化的算法,以获取集中在清洁或有毒数据的子集。结果是将原始数据集分成不连接子集,供我们训练相应的模型。对这些模型的表决算法确定了在较大有毒数据集中的清洁数据。我们用经验评估了我们在GTSRB和CIFAR-10数据集中进行图像分类任务的方法和技术。实验结果显示,文献中先前的脏标签和清洁标签后门攻击产生了与不相容特性相符的中毒数据集。结果还显示,我们的防御把攻击成功率降低到134个攻击率以下,在165个TRA的假设中确定了清洁度,只有2 %。