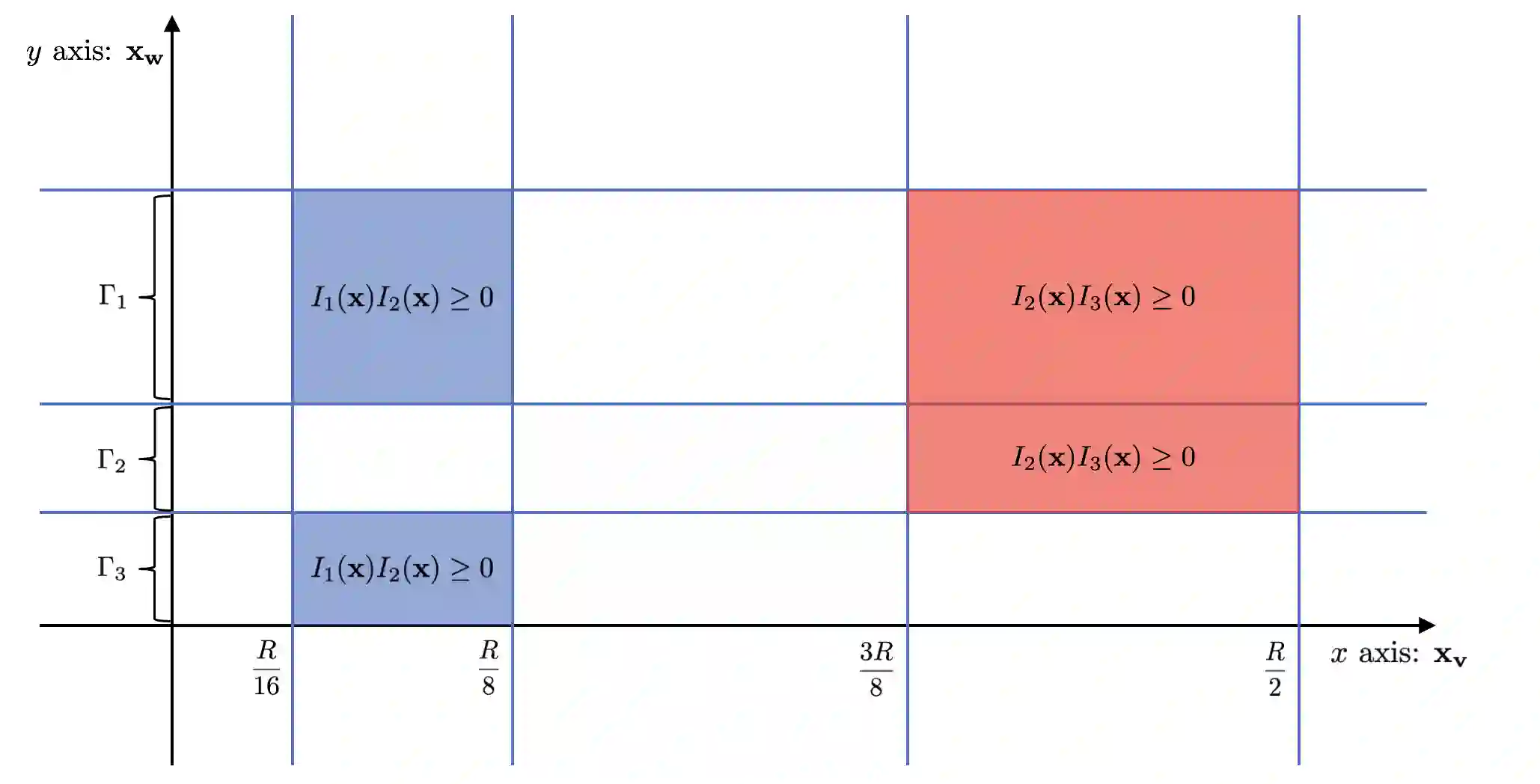
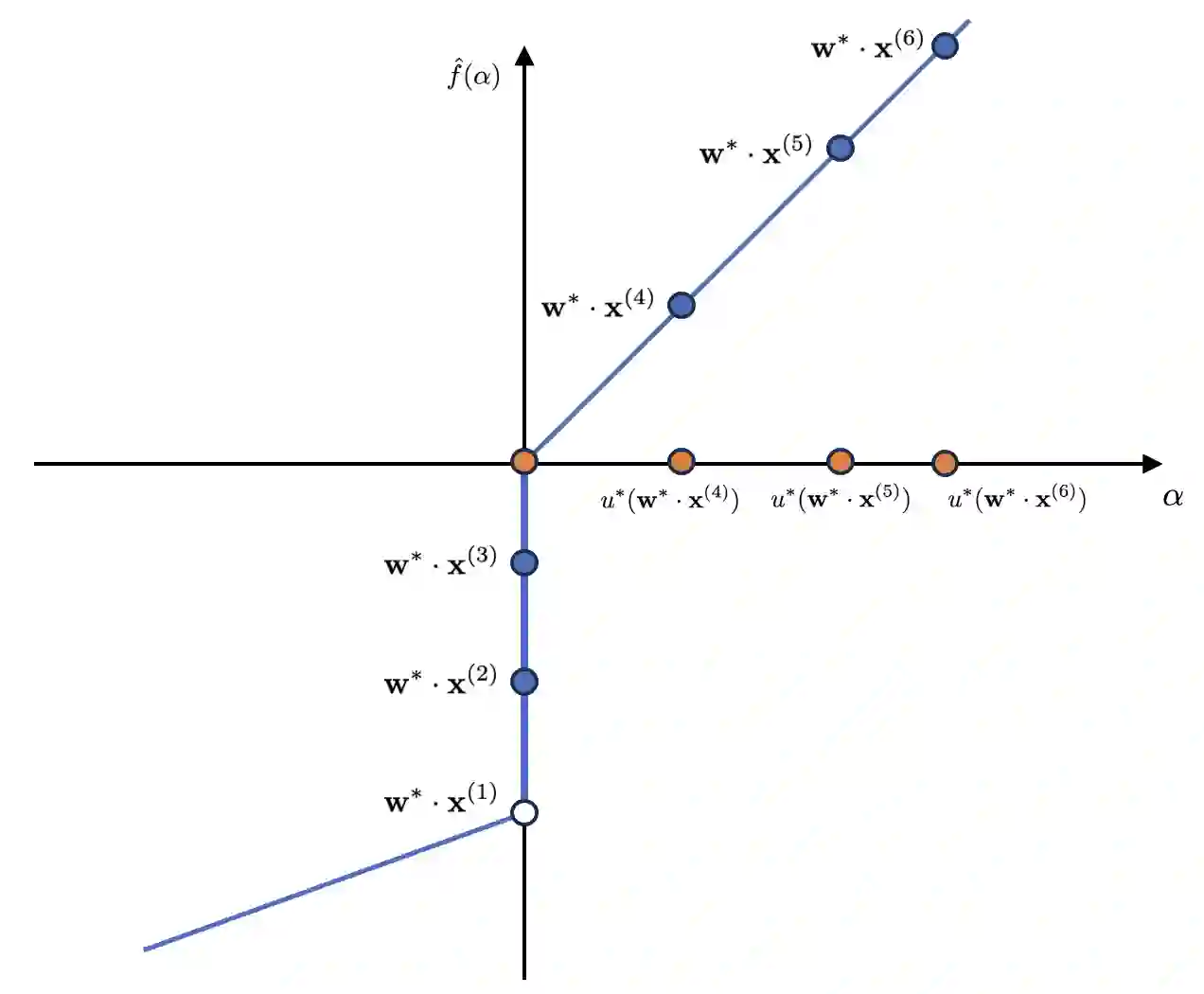
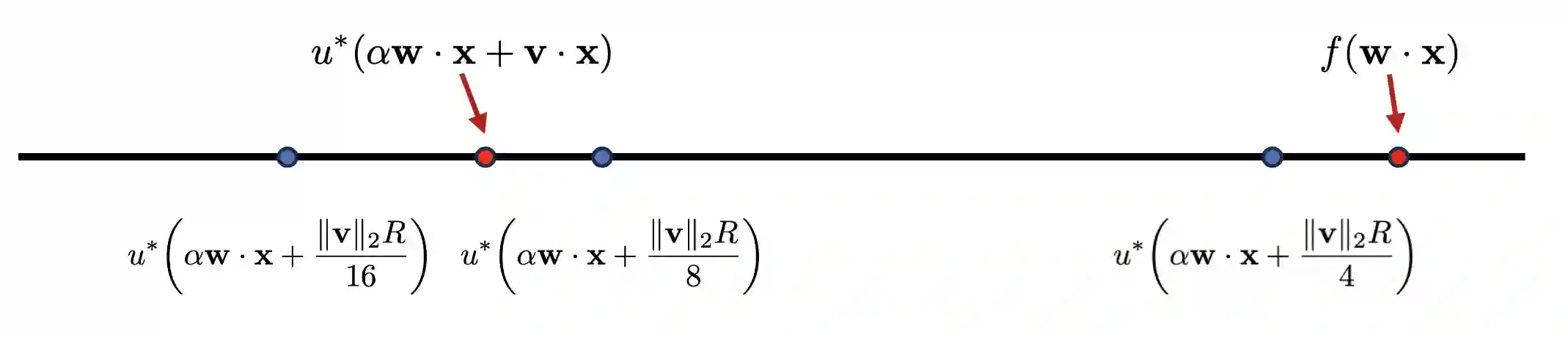We study the problem of learning Single-Index Models under the $L_2^2$ loss in the agnostic model. We give an efficient learning algorithm, achieving a constant factor approximation to the optimal loss, that succeeds under a range of distributions (including log-concave distributions) and a broad class of monotone and Lipschitz link functions. This is the first efficient constant factor approximate agnostic learner, even for Gaussian data and for any nontrivial class of link functions. Prior work for the case of unknown link function either works in the realizable setting or does not attain constant factor approximation. The main technical ingredient enabling our algorithm and analysis is a novel notion of a local error bound in optimization that we term alignment sharpness and that may be of broader interest.
翻译:暂无翻译