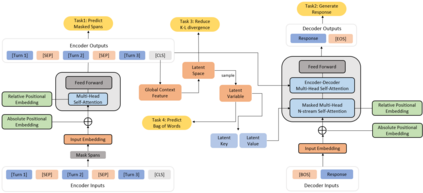
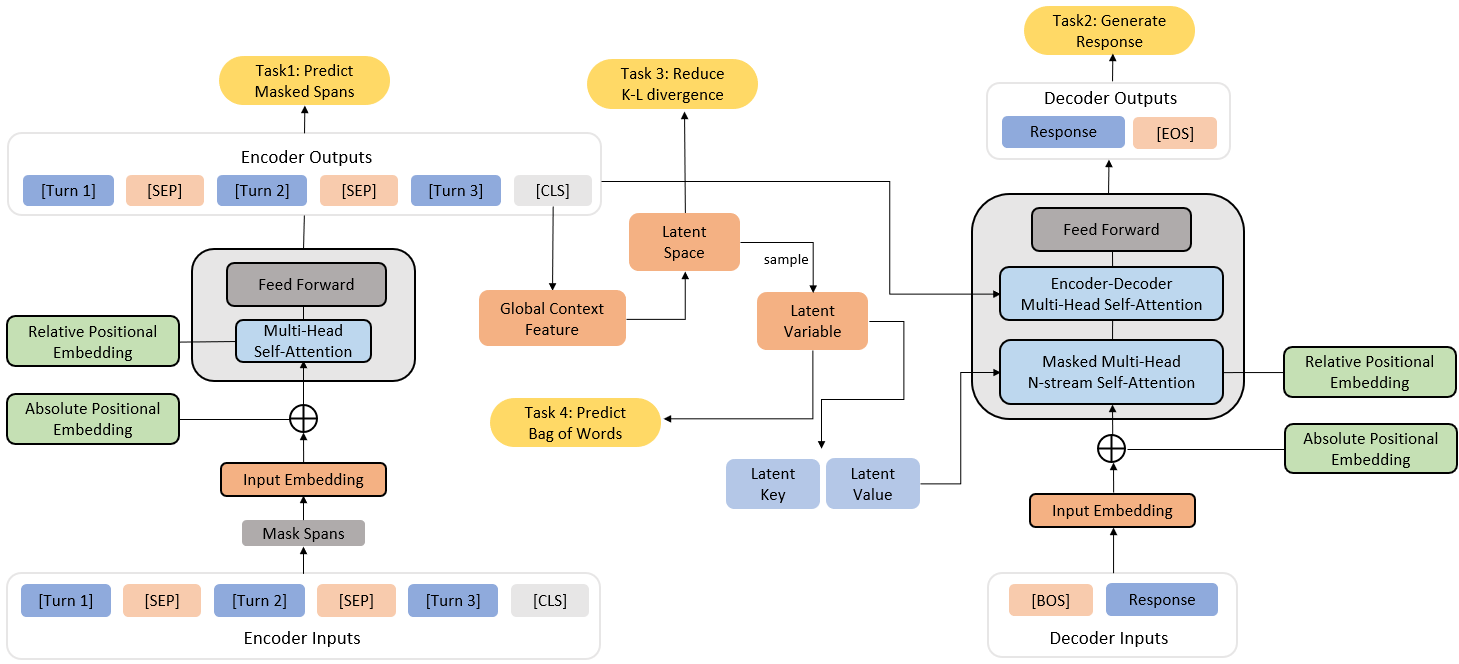
Dialog response generation in open domain is an important research topic where the main challenge is to generate relevant and diverse responses. In this paper, we propose a new dialog pre-training framework called DialogVED, which introduces continuous latent variables into the enhanced encoder-decoder pre-training framework to increase the relevance and diversity of responses. With the help of a large dialog corpus (Reddit), we pre-train the model using the following 4 tasks, used in training language models (LMs) and Variational Autoencoders (VAEs) literature: 1) masked language model; 2) response generation; 3) bag-of-words prediction; and 4) KL divergence reduction. We also add additional parameters to model the turn structure in dialogs to improve the performance of the pre-trained model. We conduct experiments on PersonaChat, DailyDialog, and DSTC7-AVSD benchmarks for response generation. Experimental results show that our model achieves the new state-of-the-art results on all these datasets.
翻译:在开放域生成对话框是一个重要的研究课题,其主要挑战是产生相关和多样的响应。在本文中,我们提议一个新的对话前培训框架,称为 " 对话框 ",将连续的潜在变量引入强化的编码器-编码器前培训框架,以提高回应的相关性和多样性。在大型对话框(REdddit)的帮助下,我们用以下4项任务对模型进行预演,这些任务用于培训语言模型(LMS)和变式自动编码器(VAEs)文献:1) 遮盖语言模型;2) 反应生成;3) 字包预测;4) KL差异减少。我们还增加了其他参数,以模拟对话的转动结构,以改进预先培训模型的性能。我们在人文计算机、Daidialog和DST7-AVSD基准方面进行了实验,以生成反应。实验结果显示,我们的模型在所有这些数据集上都取得了新的状态结果。