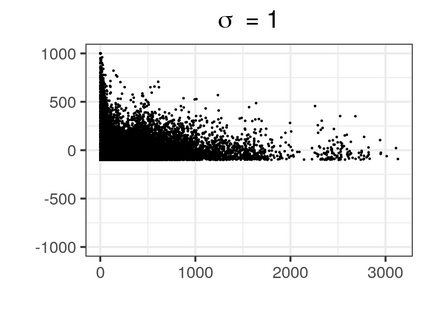
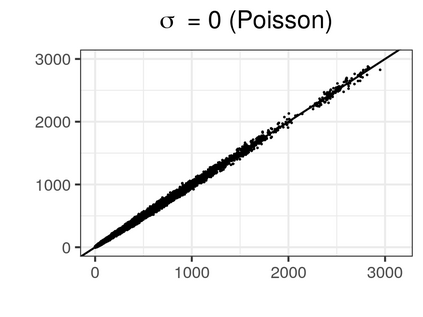
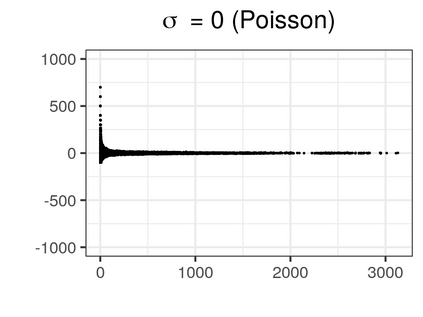
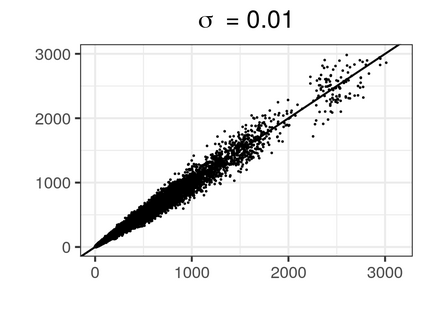
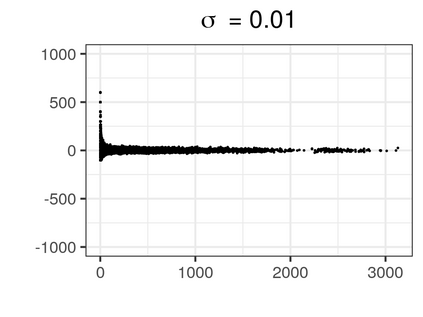
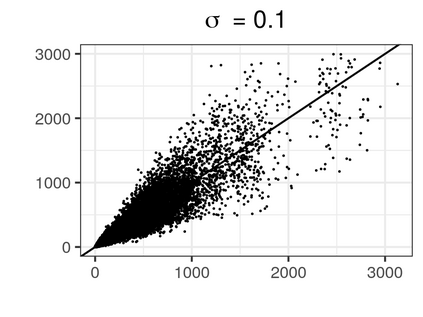
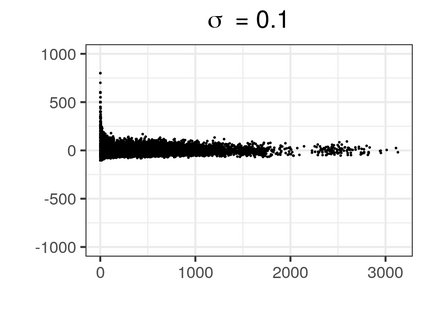
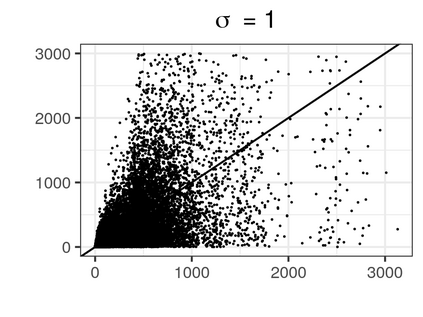
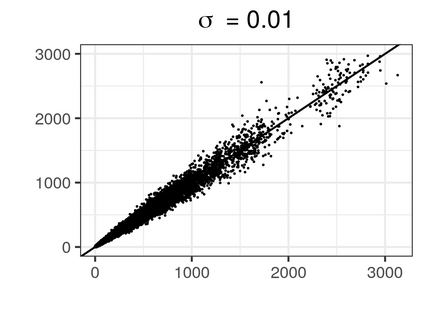
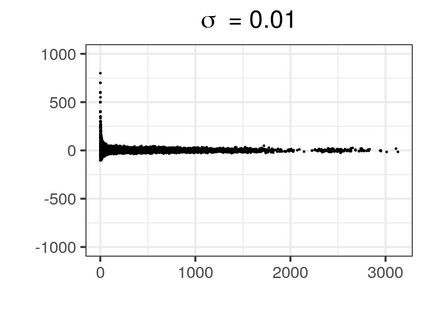
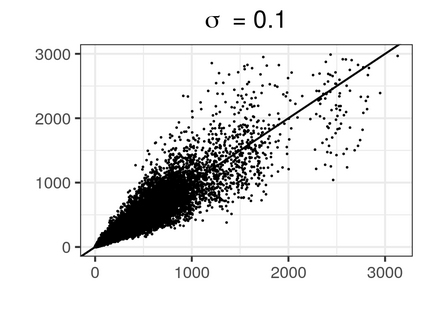
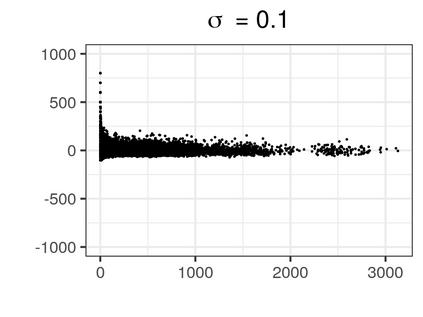
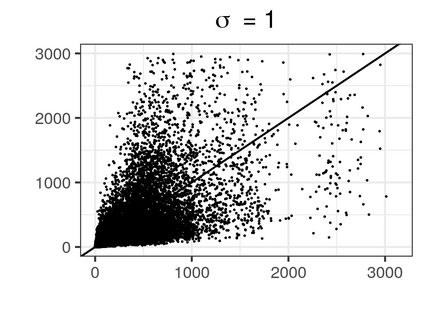
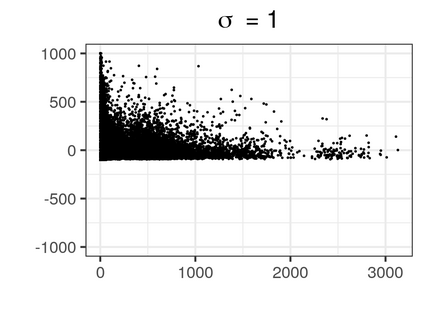
Over the past three decades, synthetic data methods for statistical disclosure control have continually evolved, but mainly within the domain of survey data sets. There are certain characteristics of administrative databases, such as their size, which present challenges from a synthesis perspective and require special attention. This paper, through the fitting of saturated count models, presents a synthesis method that is suitable for administrative databases that is tuned by two parameters. The method allows large categorical data sets to be synthesized quickly and allows risk and utility metrics to be satisfied a priori, that is, prior to synthetic data generation. The paper explores how the flexibility afforded by two-parameter count models (the negative binomial and Poisson-inverse Gaussian) can be utilised to protect respondents' - especially uniques' - privacy in synthetic data. Finally, an empirical example is carried out through the synthesis of a database which can be viewed as a good substitute to the English School Census.
翻译:在过去三十年中,统计披露控制的综合数据方法不断演变,但主要是在调查数据集的领域内。行政数据库的某些特点,例如其规模,从综合角度提出了挑战,需要特别注意。本文件通过安装饱和计数模型,提出了适合行政数据库的合成方法,该方法有两个参数加以调整。该方法允许快速合成大量绝对数据集,并允许先验地(即在合成数据生成之前)满足风险和实用度量。该文件探讨了如何利用两个参数计数模型(负比诺莫和普瓦松-伊弗斯高斯)提供的灵活性来保护答复者在合成数据中的隐私,特别是独特的隐私。最后,通过综合一个可以被视为英语学校普查的良好替代数据,来开展一个经验范例。