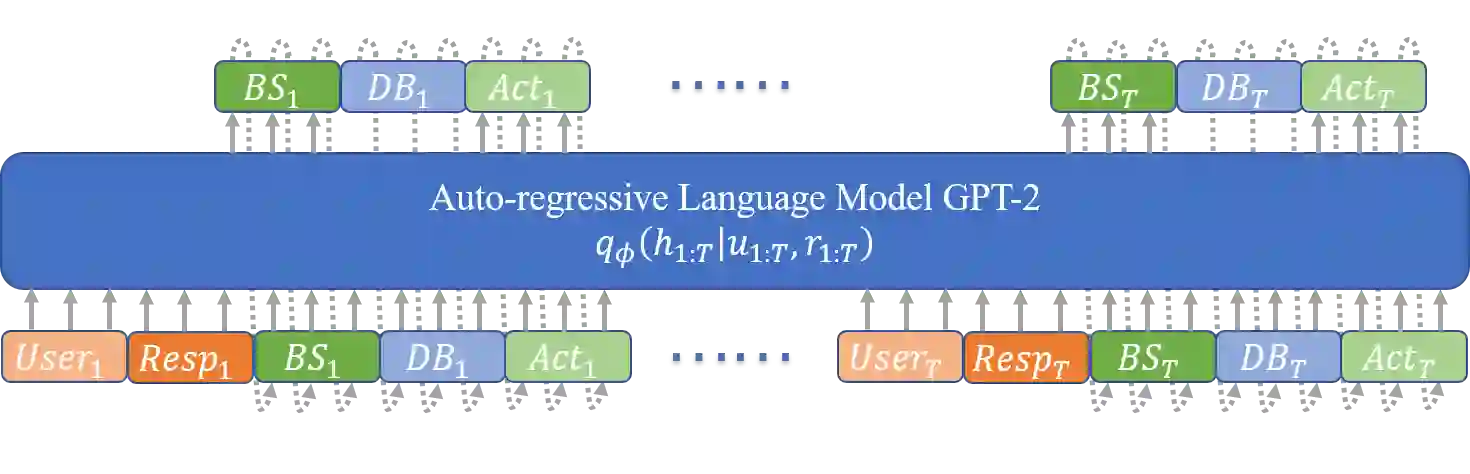
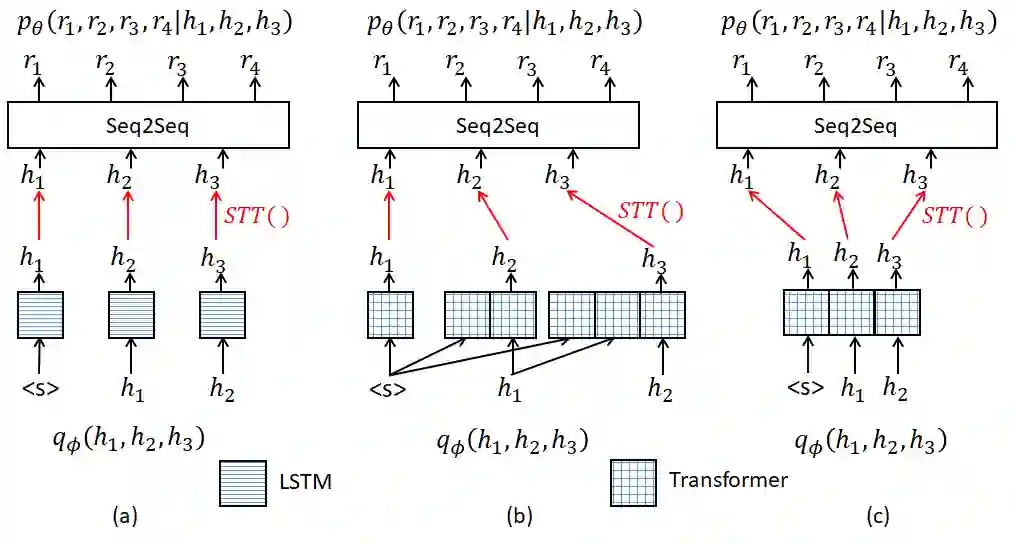
Recently, two approaches, fine-tuning large pre-trained language models and variational training, have attracted significant interests, separately, for semi-supervised end-to-end task-oriented dialog (TOD) systems. In this paper, we propose Variational Latent-State GPT model (VLS-GPT), which is the first to combine the strengths of the two approaches. Among many options of models, we propose the generative model and the inference model for variational learning of the end-to-end TOD system, both as auto-regressive language models based on GPT-2, which can be further trained over a mix of labeled and unlabeled dialog data in a semi-supervised manner. We develop the strategy of sampling-then-forward-computation, which successfully overcomes the memory explosion issue of using GPT in variational learning and speeds up training. Semi-supervised TOD experiments are conducted on two benchmark multi-domain datasets of different languages - MultiWOZ2.1 and CrossWOZ. VLS-GPT is shown to significantly outperform both supervised-only and semi-supervised baselines.
翻译:最近,两种方法,即微调大型预先培训的语言模型和变式培训,分别吸引了半监督端对端任务导向对话(TOD)系统的重大兴趣。在本文件中,我们提出了变式中端状态GPT模型(VLS-GPT),这是将两种方法的优势结合起来的第一个办法。在许多模式备选方案中,我们提出了归因模型和对端TOD系统变异学习的推导模型,两者都是以GPT-2为基础的自动反向语言模型,可以以半监督方式对标签和未标签的对话框数据组合进行进一步的培训。我们制定了取样前向前转换战略,成功地克服了在变式学习中使用GPT的记忆爆炸问题,加快了培训速度。在两种不同语言的基准多域数据集-MUDWOZ2.1和CrossWOZ-VLS-GPT实验中,显示VLS-GPT大大超越了监督和半超级基线。