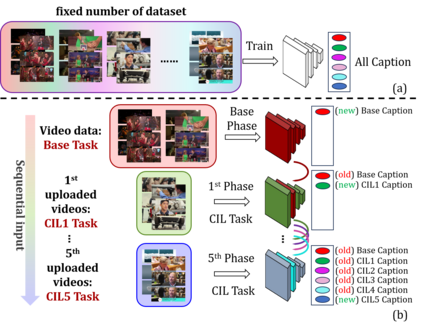
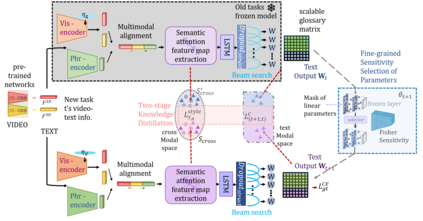
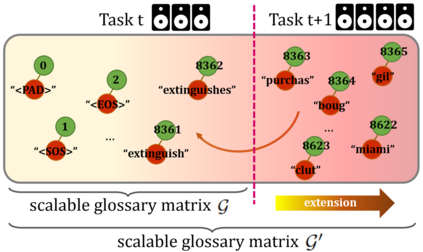
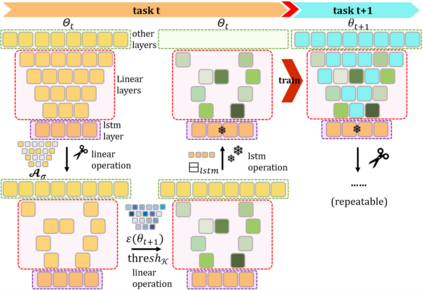
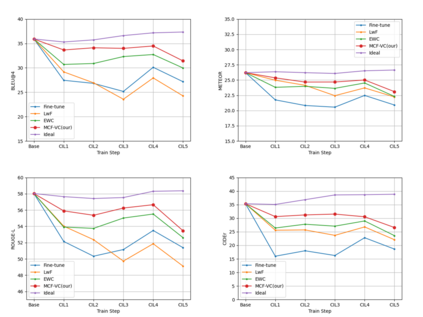
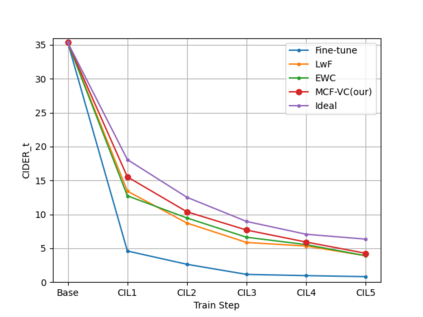
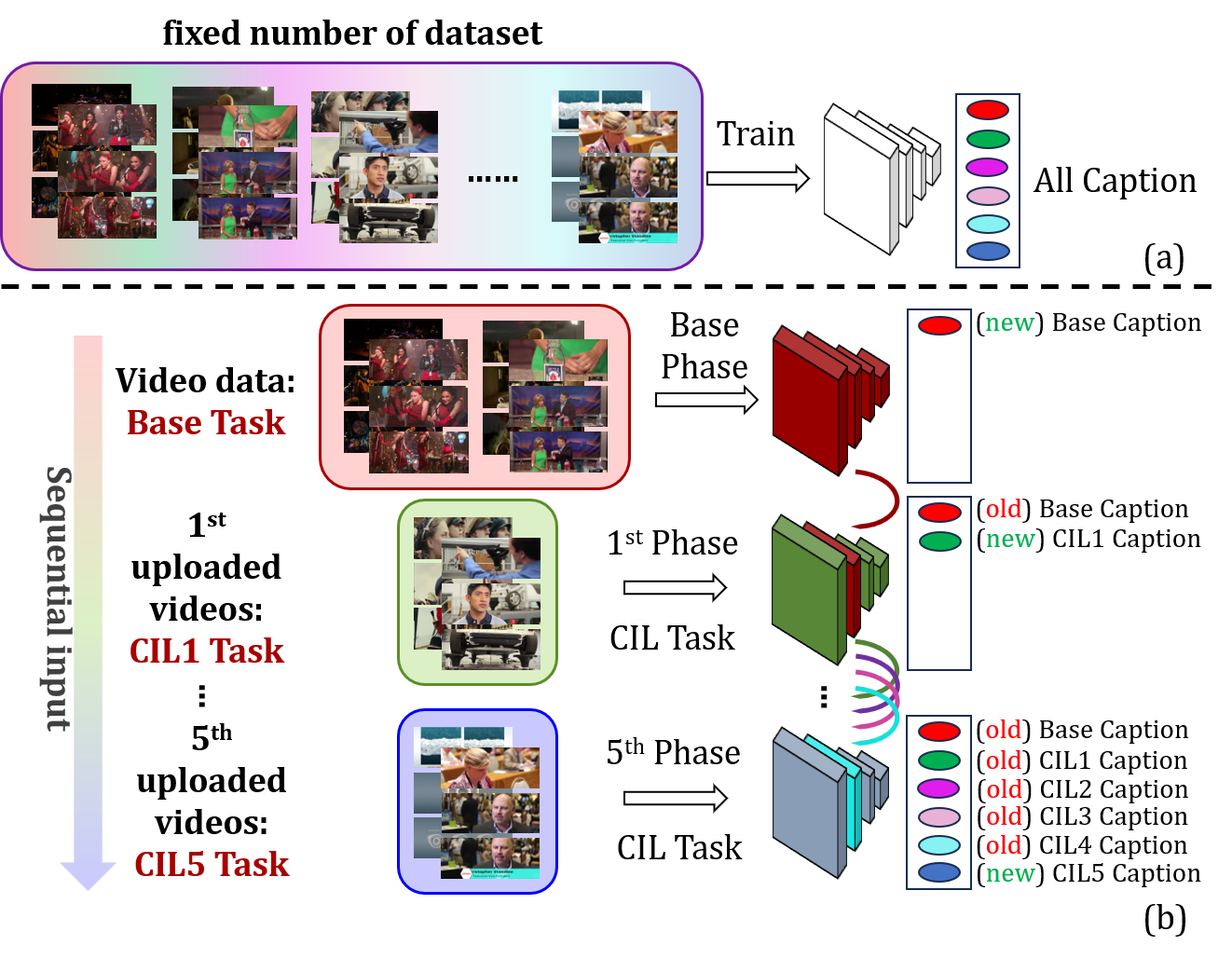
To address the problem of catastrophic forgetting due to the invisibility of old categories in sequential input, existing work based on relatively simple categorization tasks has made some progress. In contrast, video captioning is a more complex task in multimodal scenario, which has not been explored in the field of incremental learning. After identifying this stability-plasticity problem when analyzing video with sequential input, we originally propose a method to Mitigate Catastrophic Forgetting in class-incremental learning for multimodal Video Captioning (MCF-VC). As for effectively maintaining good performance on old tasks at the macro level, we design Fine-grained Sensitivity Selection (FgSS) based on the Mask of Linear's Parameters and Fisher Sensitivity to pick useful knowledge from old tasks. Further, in order to better constrain the knowledge characteristics of old and new tasks at the specific feature level, we have created the Two-stage Knowledge Distillation (TsKD), which is able to learn the new task well while weighing the old task. Specifically, we design two distillation losses, which constrain the cross modal semantic information of semantic attention feature map and the textual information of the final outputs respectively, so that the inter-model and intra-model stylized knowledge of the old class is retained while learning the new class. In order to illustrate the ability of our model to resist forgetting, we designed a metric CIDER_t to detect the stage forgetting rate. Our experiments on the public dataset MSR-VTT show that the proposed method significantly resists the forgetting of previous tasks without replaying old samples, and performs well on the new task.
翻译:暂无翻译