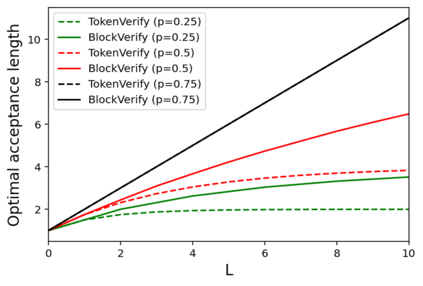
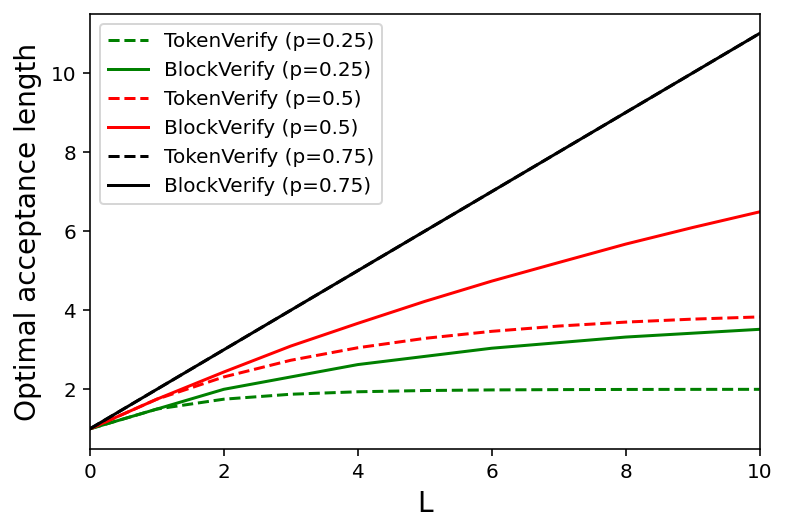
Speculative decoding has shown to be an effective method for lossless acceleration of large language models (LLMs) during inference. In each iteration, the algorithm first uses a smaller model to draft a block of tokens. The tokens are then verified by the large model in parallel and only a subset of tokens will be kept to guarantee that the final output follows the distribution of the large model. In all of the prior speculative decoding works, the draft verification is performed token-by-token independently. In this work, we propose a better draft verification algorithm that provides additional wall-clock speedup without incurring additional computation cost and draft tokens. We first formulate the draft verification step as a block-level optimal transport problem. The block-level formulation allows us to consider a wider range of draft verification algorithms and obtain a higher number of accepted tokens in expectation in one draft block. We propose a verification algorithm that achieves the optimal accepted length for the block-level transport problem. We empirically evaluate our proposed block-level verification algorithm in a wide range of tasks and datasets, and observe consistent improvements in wall-clock speedup when compared to token-level verification algorithm. To the best of our knowledge, our work is the first to establish improvement over speculative decoding through a better draft verification algorithm.
翻译:暂无翻译