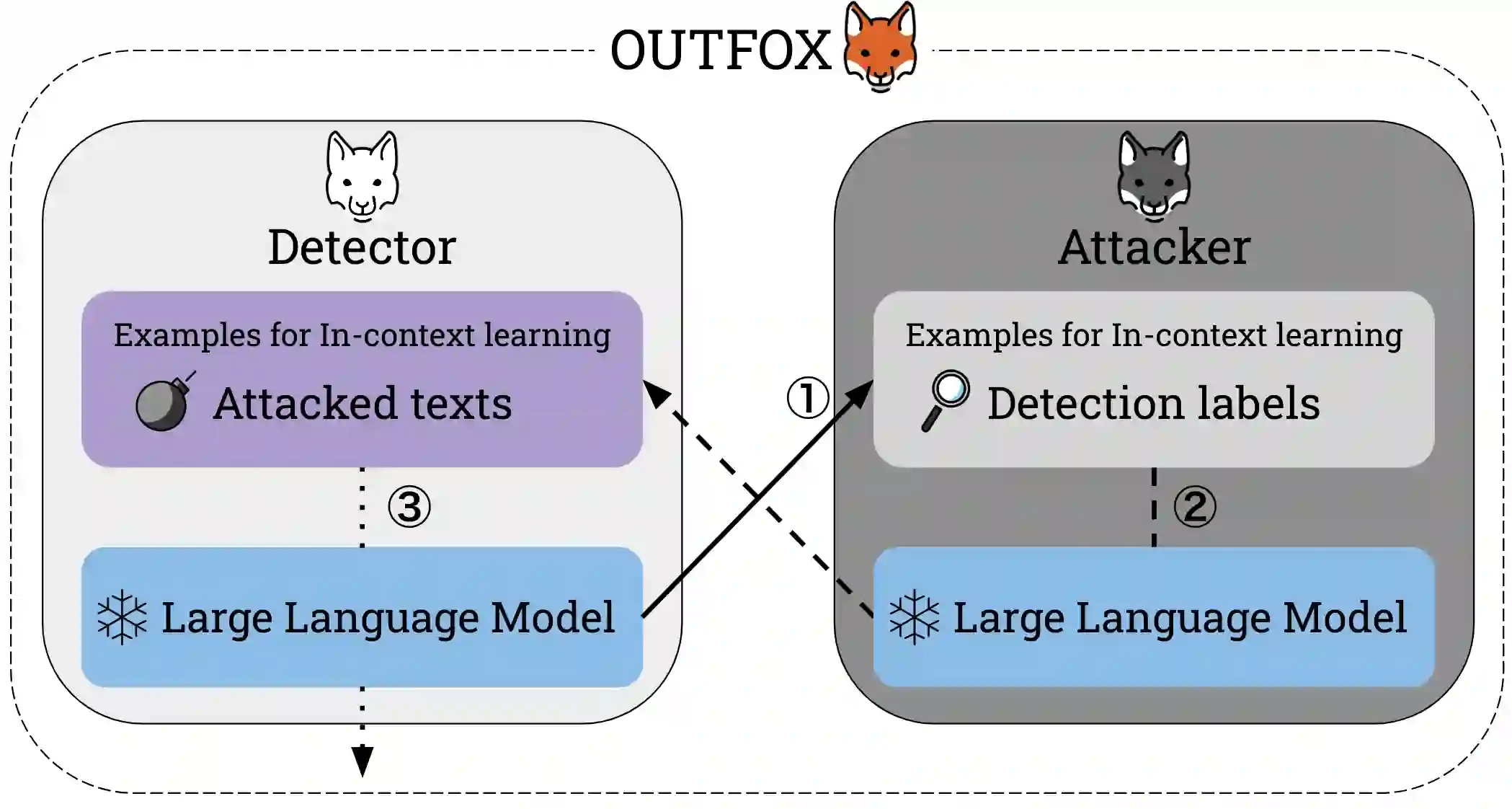
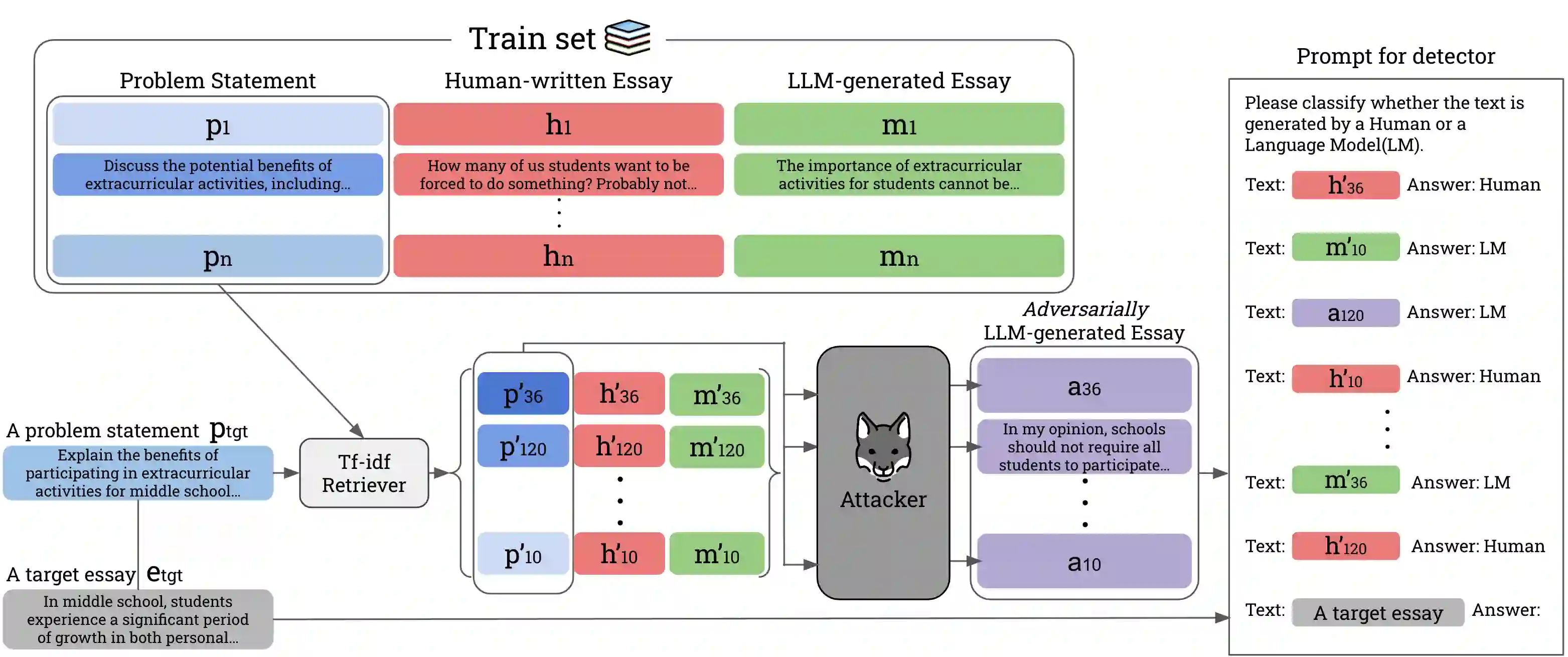
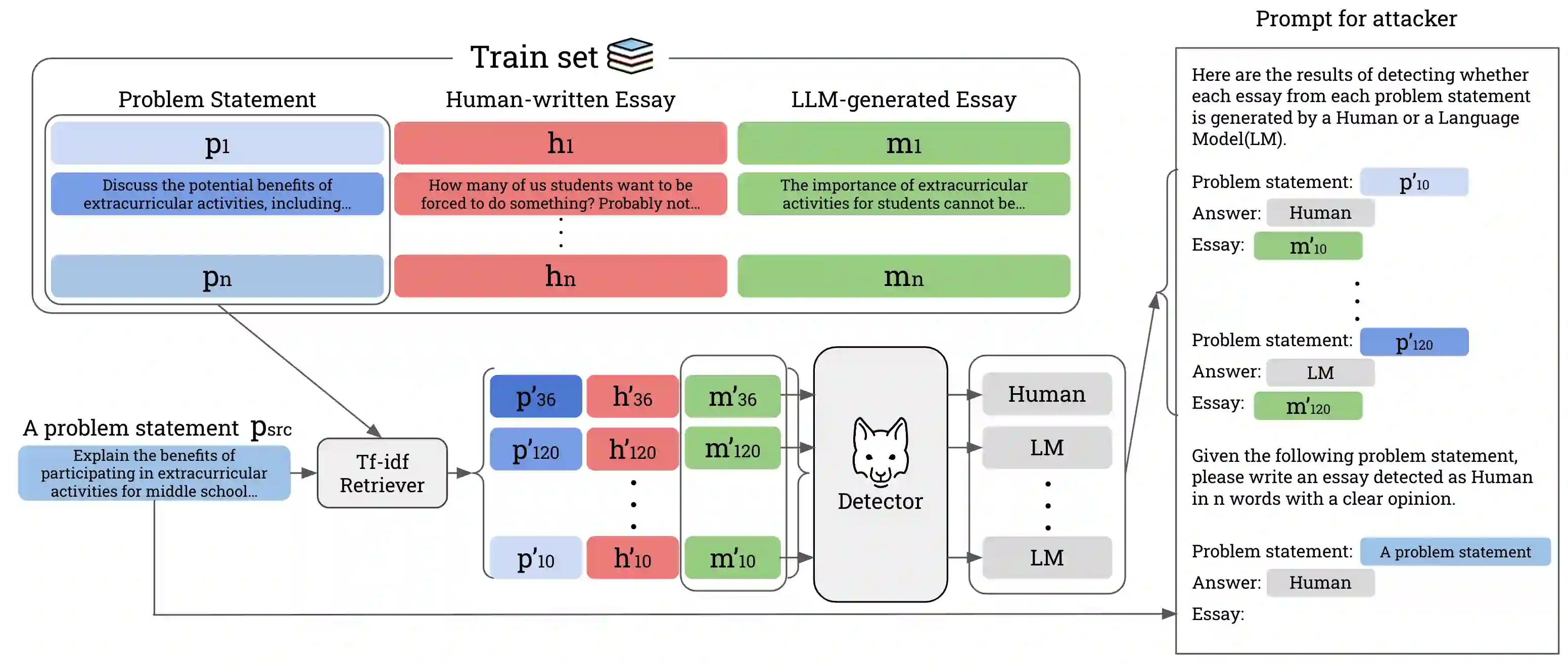
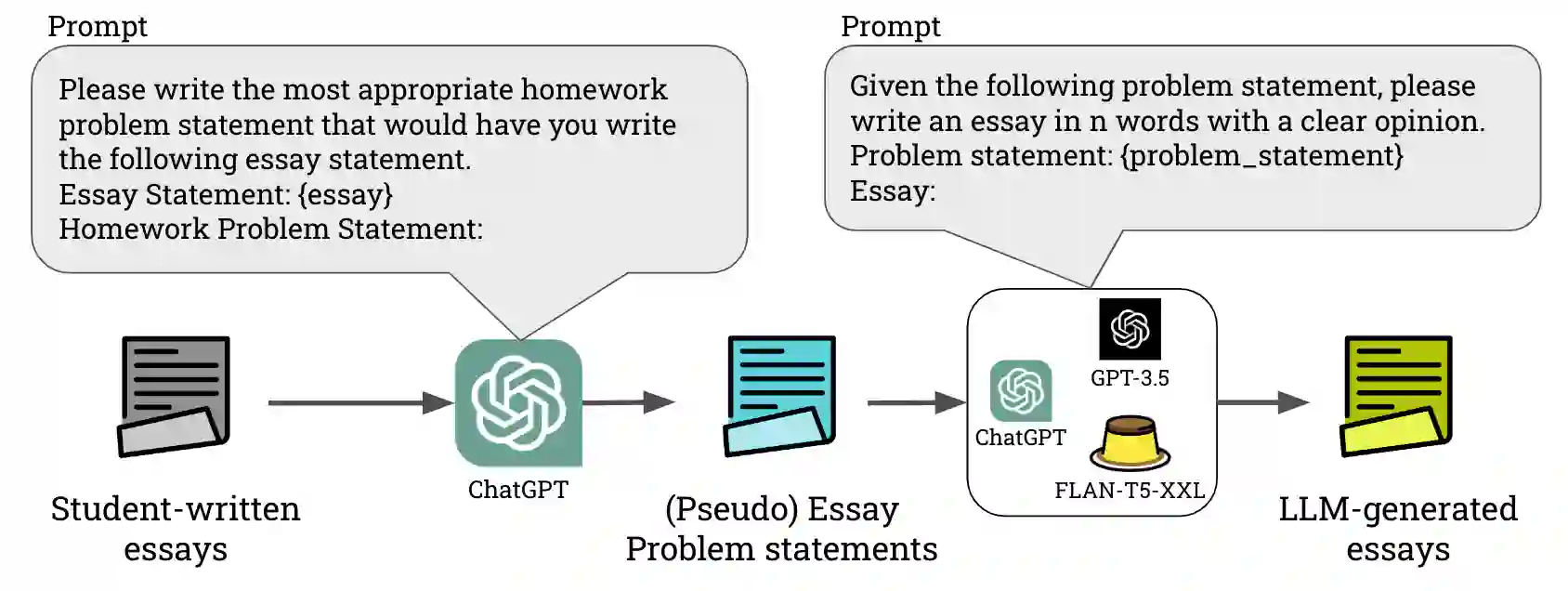
Large Language Models (LLMs) have achieved human-level fluency in text generation, making it difficult to distinguish between human-written and LLM-generated texts. This poses a growing risk of misuse of LLMs and demands the development of detectors to identify LLM-generated texts. However, existing detectors degrade detection accuracy by simply paraphrasing LLM-generated texts. Furthermore, the effectiveness of these detectors in real-life situations, such as when students use LLMs for writing homework assignments (e.g., essays) and quickly learn how to evade these detectors, has not been explored. In this paper, we propose OUTFOX, a novel framework that improves the robustness of LLM-generated-text detectors by allowing both the detector and the attacker to consider each other's output and apply this to the domain of student essays. In our framework, the attacker uses the detector's prediction labels as examples for in-context learning and adversarially generates essays that are harder to detect. While the detector uses the adversarially generated essays as examples for in-context learning to learn to detect essays from a strong attacker. Our experiments show that our proposed detector learned in-context from the attacker improves the detection performance on the attacked dataset by up to +41.3 point F1-score. While our proposed attacker can drastically degrade the performance of the detector by up to -57.0 point F1-score compared to the paraphrasing method.
翻译:暂无翻译