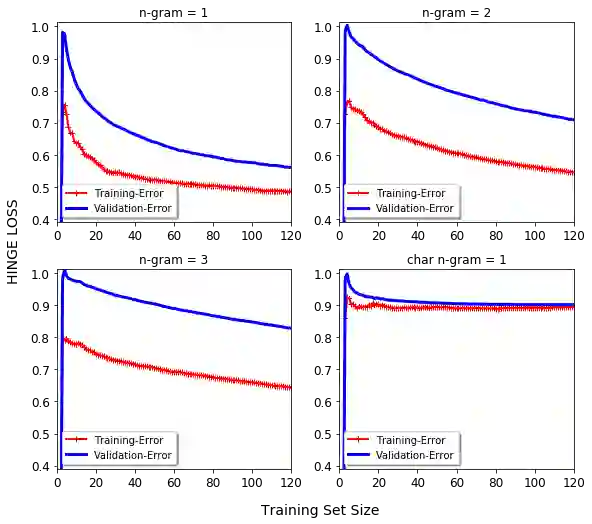
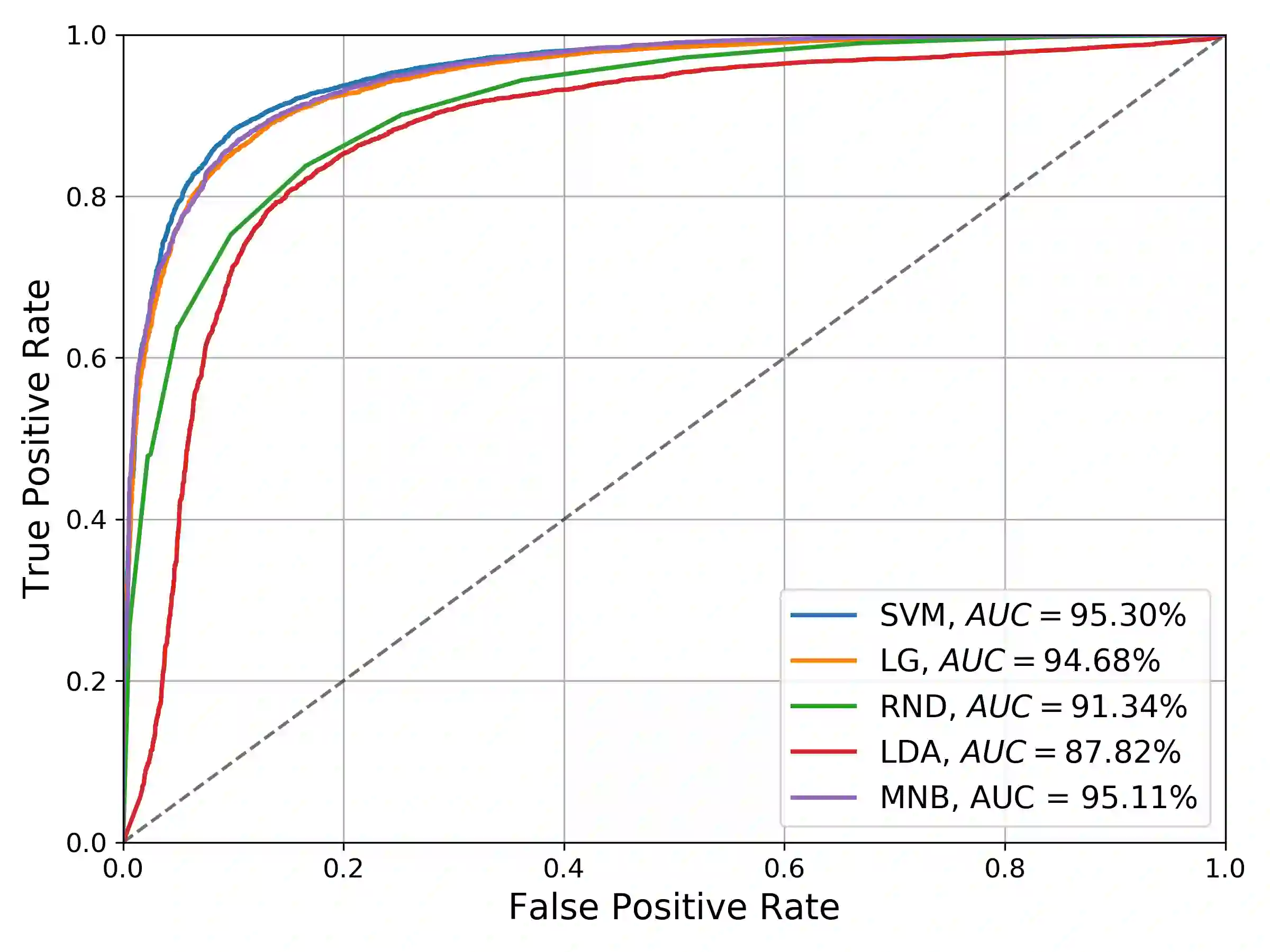
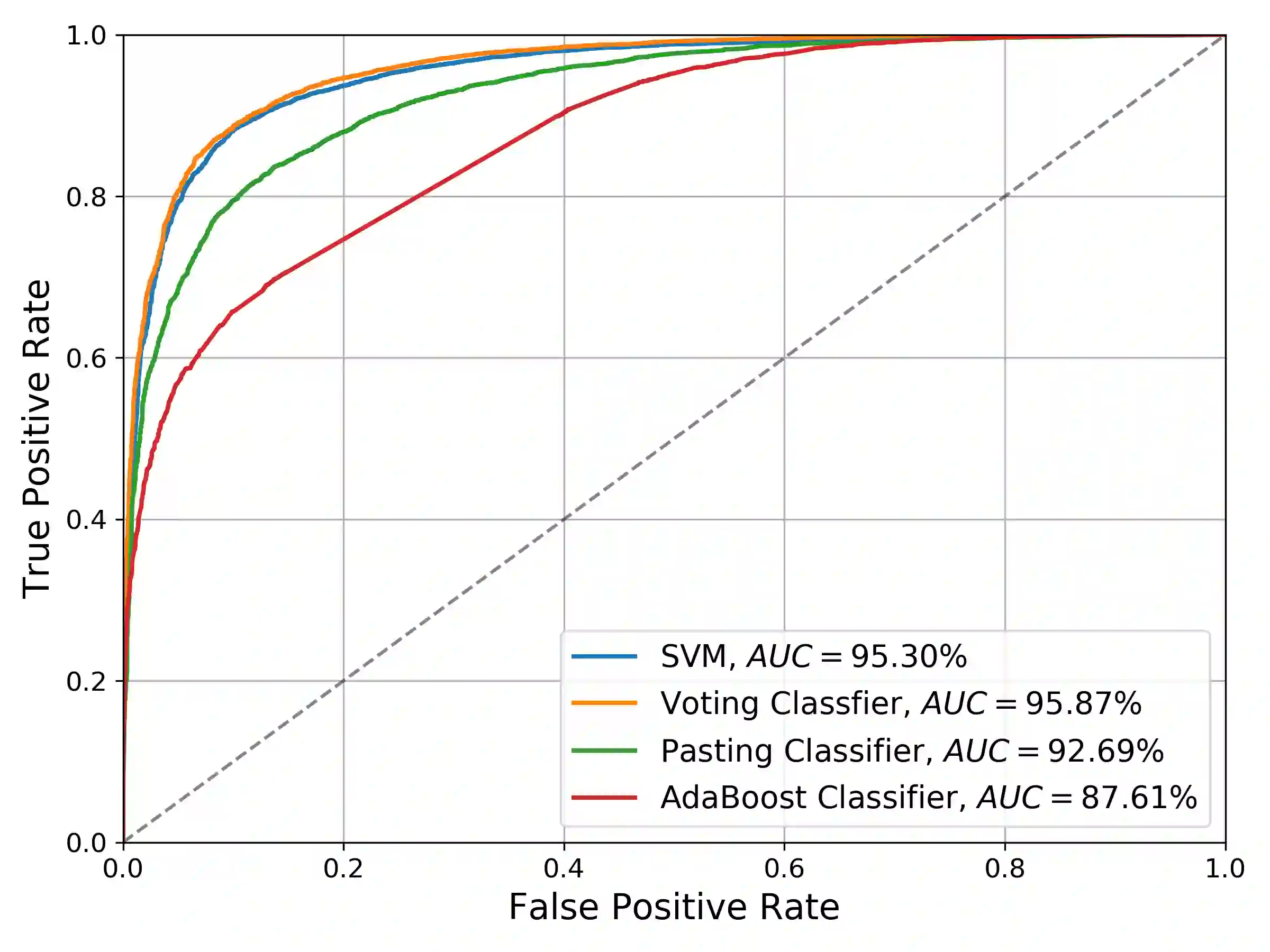
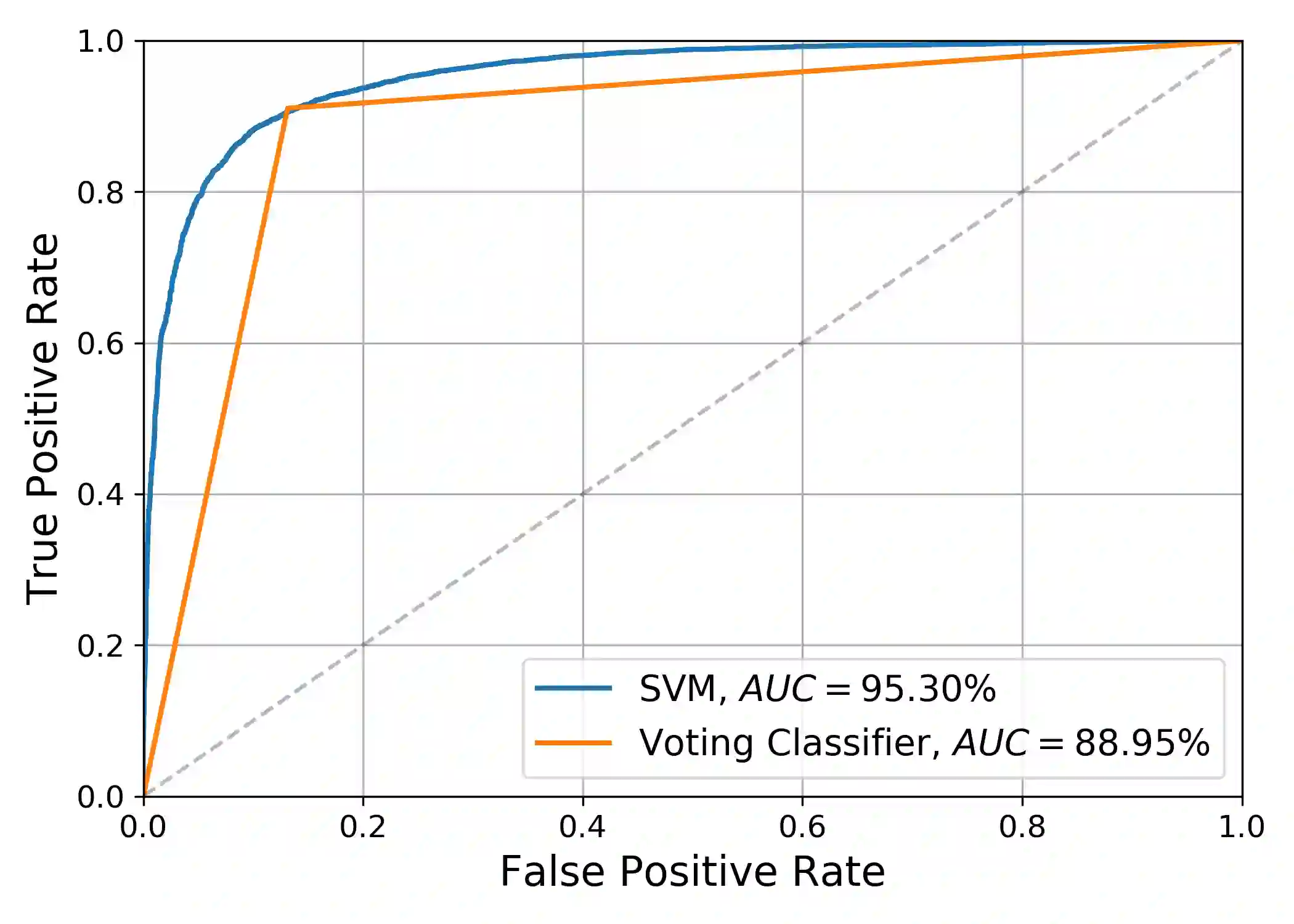
Over recent years a lot of research papers and studies have been published on the development of effective approaches that benefit from a large amount of user-generated content and build intelligent predictive models on top of them. This research applies machine learning-based approaches to tackle the hurdles that come with Persian user-generated textual content. Unfortunately, there is still inadequate research in exploiting machine learning approaches to classify/cluster Persian text. Further, analyzing Persian text suffers from a lack of resources; specifically from datasets and text manipulation tools. Since the syntax and semantics of the Persian language is different from English and other languages, the available resources from these languages are not instantly usable for Persian. In addition, recognition of nouns and pronouns, parts of speech tagging, finding words' boundary, stemming or character manipulations for Persian language are still unsolved issues that require further studying. Therefore, efforts have been made in this research to address some of the challenges. This presented approach uses a machine-translated datasets to conduct sentiment analysis for the Persian language. Finally, the dataset has been rehearsed with different classifiers and feature engineering approaches. The results of the experiments have shown promising state-of-the-art performance in contrast to the previous efforts; the best classifier was Support Vector Machines which achieved a precision of 91.22%, recall of 91.71%, and F1 score of 91.46%.
翻译:近些年来,已经发表了大量研究论文和研究报告,内容涉及如何制定有效方法,从大量用户生成的内容中受益,并在上面建立智能预测模型。这项研究运用机器学习方法,解决波斯用户生成的文本内容带来的障碍。不幸的是,在利用机器学习方法对波斯文本进行分类/集群方面,研究仍然不够充分。此外,分析波斯文本缺乏资源,具体来自数据集和文本处理工具。由于波斯语的语法和语义不同于英语和其他语言,因此这些语言的现有资源不能立即用于波斯语。此外,对名词和代词的识别、语言标记、语言界限、波斯语言的断层或字符操控等部分的识别,仍然是有待进一步研究的未解问题。因此,在这项研究中已经努力应对一些挑战。提出的方法使用了机器翻译的数据集,1 用于对波斯语进行情绪分析。最后,数据集经过不同分类和地貌工程学的预选用资源排练。此外,对名词和标语的标语学方法部分、标语的标本部分、查找界限的界限部分、对波斯语言的精确度的精确度测试结果显示有希望的成绩。