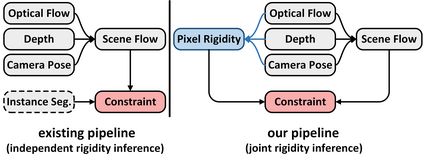
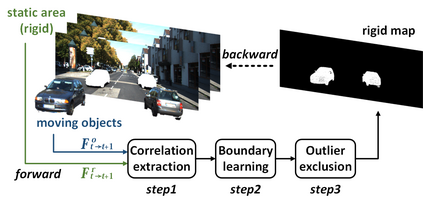
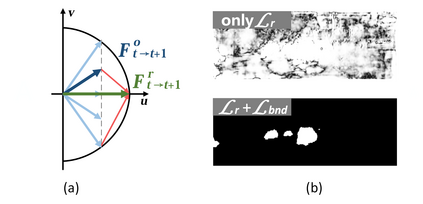
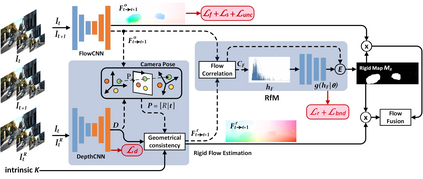
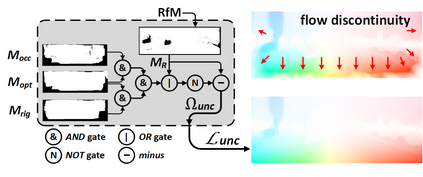
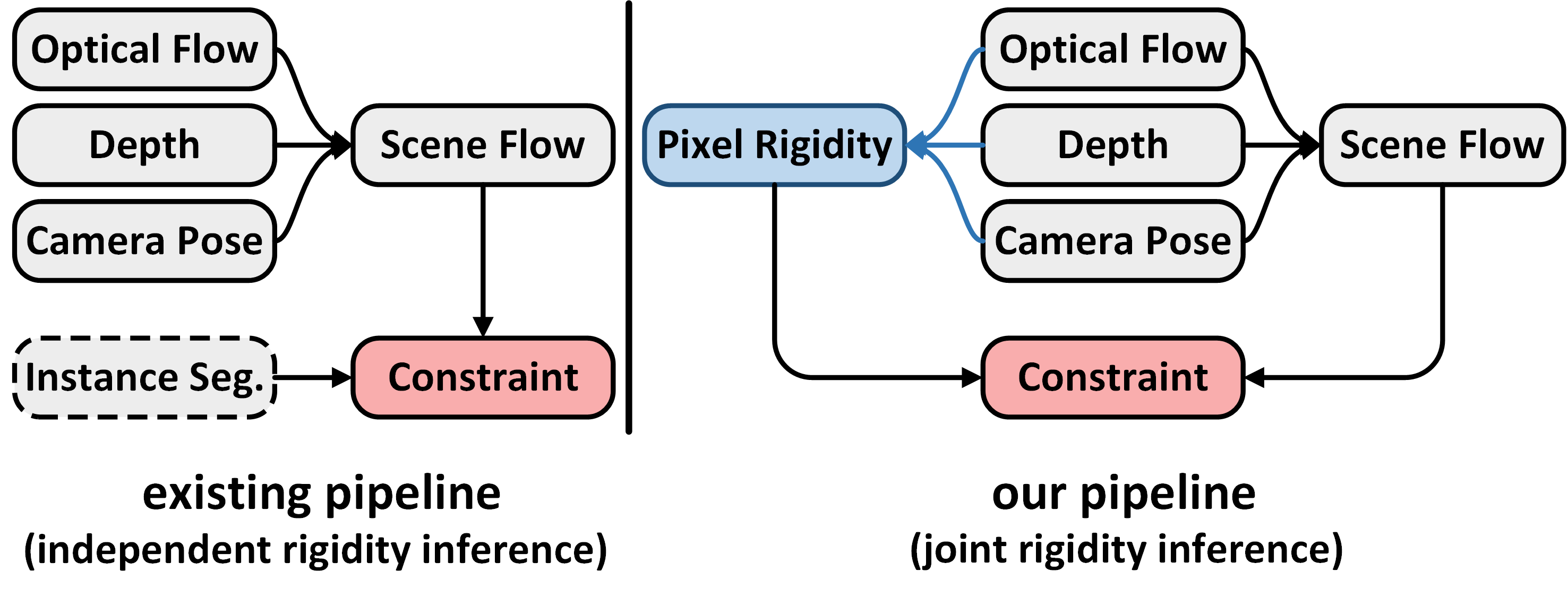
This paper addresses the challenging unsupervised scene flow estimation problem by jointly learning four low-level vision sub-tasks: optical flow $\textbf{F}$, stereo-depth $\textbf{D}$, camera pose $\textbf{P}$ and motion segmentation $\textbf{S}$. Our key insight is that the rigidity of the scene shares the same inherent geometrical structure with object movements and scene depth. Hence, rigidity from $\textbf{S}$ can be inferred by jointly coupling $\textbf{F}$, $\textbf{D}$ and $\textbf{P}$ to achieve more robust estimation. To this end, we propose a novel scene flow framework named EffiScene with efficient joint rigidity learning, going beyond the existing pipeline with independent auxiliary structures. In EffiScene, we first estimate optical flow and depth at the coarse level and then compute camera pose by Perspective-$n$-Points method. To jointly learn local rigidity, we design a novel Rigidity From Motion (RfM) layer with three principal components: \emph{}{(i)} correlation extraction; \emph{}{(ii)} boundary learning; and \emph{}{(iii)} outlier exclusion. Final outputs are fused based on the rigid map $M_R$ from RfM at finer levels. To efficiently train EffiScene, two new losses $\mathcal{L}_{bnd}$ and $\mathcal{L}_{unc}$ are designed to prevent trivial solutions and to regularize the flow boundary discontinuity. Extensive experiments on scene flow benchmark KITTI show that our method is effective and significantly improves the state-of-the-art approaches for all sub-tasks, i.e. optical flow ($5.19 \rightarrow 4.20$), depth estimation ($3.78 \rightarrow 3.46$), visual odometry ($0.012 \rightarrow 0.011$) and motion segmentation ($0.57 \rightarrow 0.62$).
翻译:本文通过联合学习四个低水平的视觉子任务来解决具有挑战性的场景流量估算问题 {不受监督的场景流量估算问题。 因此, $\ textbf{F}$, 立体深度$\ textbf{D} $, 相机代表$\ textbf{P} $ 和运动分割 $\ textbf{S} 美元。 我们的关键洞察力是, 场景的僵硬性与物体运动和场景深度有着相同的内在几何结构。 因此, $\ textbf{S} 的僵硬性可以通过联合 来理解四个低水平的视觉 : $textb=trealbff} 美元, $xtlegalb=trealb=trealfral $.