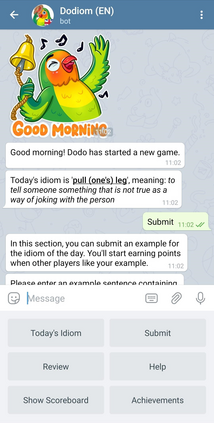
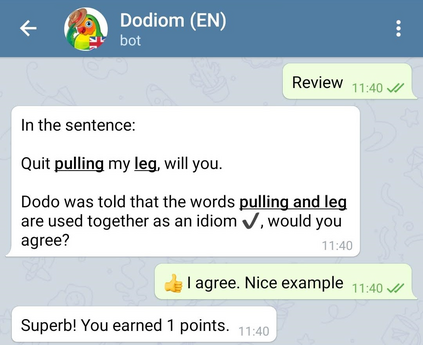
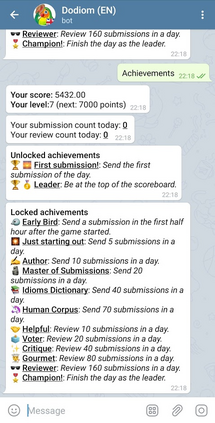
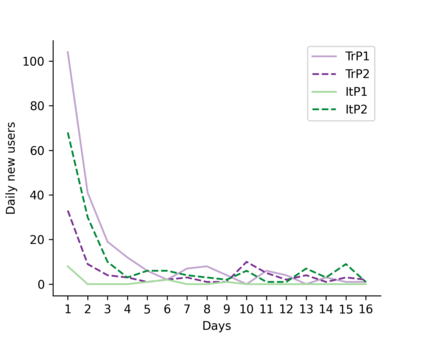
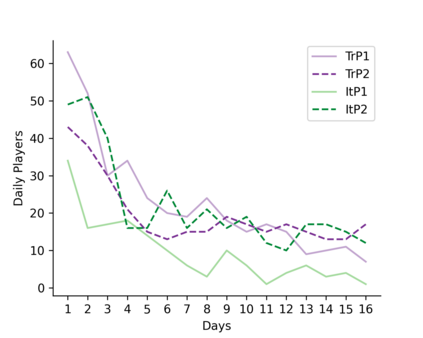
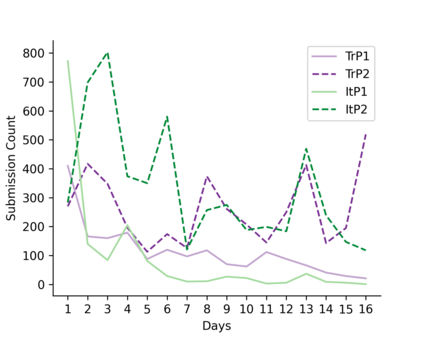
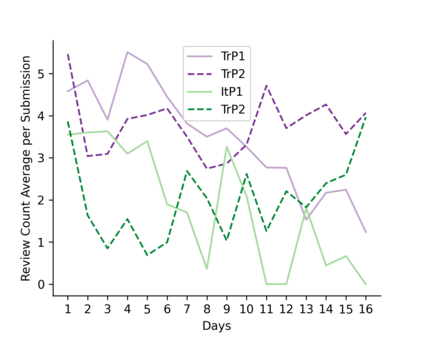
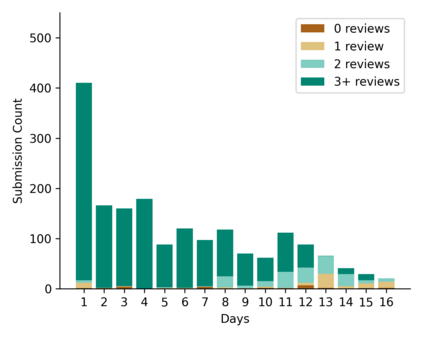
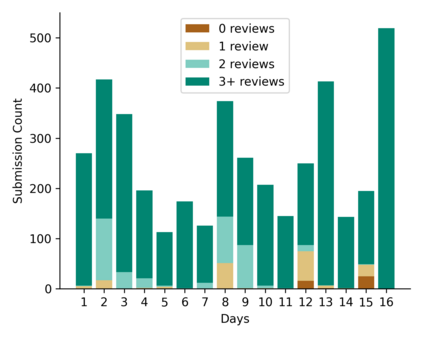
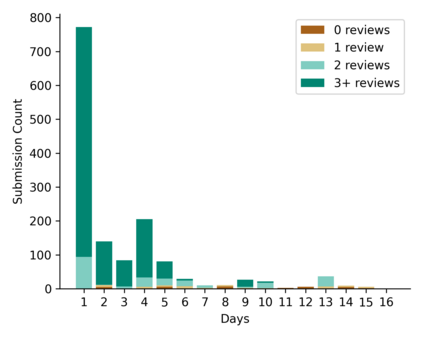
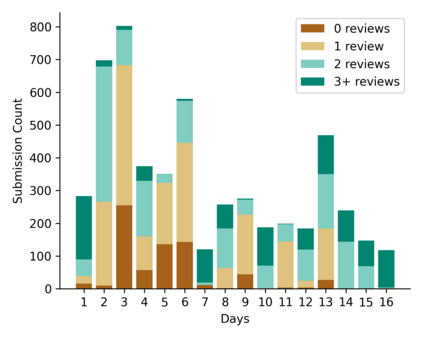
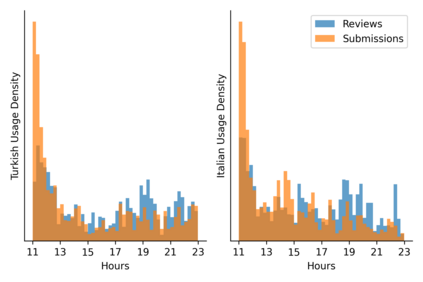
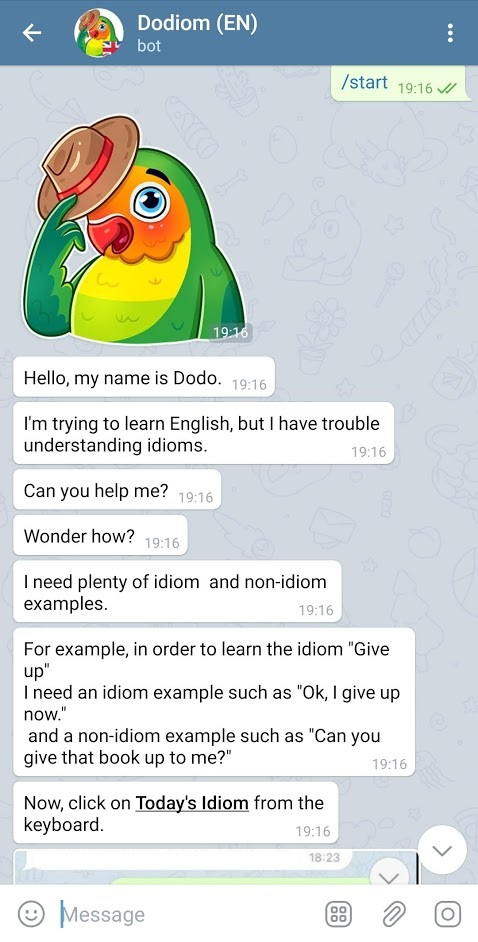
Learning idiomatic expressions is seen as one of the most challenging stages in second language learning because of their unpredictable meaning. A similar situation holds for their identification within natural language processing applications such as machine translation and parsing. The lack of high-quality usage samples exacerbates this challenge not only for humans but also for artificial intelligence systems. This article introduces a gamified crowdsourcing approach for collecting language learning materials for idiomatic expressions; a messaging bot is designed as an asynchronous multiplayer game for native speakers who compete with each other while providing idiomatic and nonidiomatic usage examples and rating other players' entries. As opposed to classical crowdprocessing annotation efforts in the field, for the first time in the literature, a crowdcreating & crowdrating approach is implemented and tested for idiom corpora construction. The approach is language independent and evaluated on two languages in comparison to traditional data preparation techniques in the field. The reaction of the crowd is monitored under different motivational means (namely, gamification affordances and monetary rewards). The results reveal that the proposed approach is powerful in collecting the targeted materials, and although being an explicit crowdsourcing approach, it is found entertaining and useful by the crowd. The approach has been shown to have the potential to speed up the construction of idiom corpora for different natural languages to be used as second language learning material, training data for supervised idiom identification systems, or samples for lexicographic studies.
翻译:由于缺乏高质量的使用样本,不仅对人而且对人工智能系统的挑战更加严重。本文章介绍了收集语言语言教学材料的拼凑众包方法,用于收集语言语言语言语言语言表达方式;信息机的设计是当地语言者因不可预测的意义而相互竞争,同时提供语言和非语言使用实例和评分其他玩家条目的不同步的多玩家游戏。结果显示,拟议的方法在收集目标材料方面是强有力的,在文献中第一次采用并测试人群制造和人群集聚方法,以建设异种公司结构。与实地传统数据编制技术相比,该方法语言是独立的,在两种语言上进行了评估。人群的反应以不同的动机语言(即,拼写支付和金钱奖励)加以监测。结果显示,拟议的方法在收集目标材料方面是强大的,在现场进行典型的人群处理时,虽然通过直接的分类方法显示,通过构建语言来进行透明的学习,可以对两种语言进行比较。