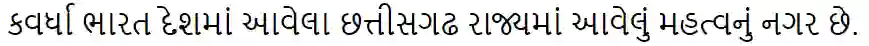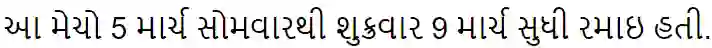We conduct an empirical study of unsupervised neural machine translation (NMT) for truly low resource languages, exploring the case when both parallel training data and compute resource are lacking, reflecting the reality of most of the world's languages and the researchers working on these languages. We propose a simple and scalable method to improve unsupervised NMT, showing how adding comparable data mined using a bilingual dictionary along with modest additional compute resource to train the model can significantly improve its performance. We also demonstrate how the use of the dictionary to code-switch monolingual data to create more comparable data can further improve performance. With this weak supervision, our best method achieves BLEU scores that improve over supervised results for English$\rightarrow$Gujarati (+18.88), English$\rightarrow$Kazakh (+5.84), and English$\rightarrow$Somali (+1.16), showing the promise of weakly-supervised NMT for many low resource languages with modest compute resource in the world. To the best of our knowledge, our work is the first to quantitatively showcase the impact of different modest compute resource in low resource NMT.
翻译:我们对真正低资源语言的未经监督的神经机器翻译(NMT)进行了实证研究,探讨了缺乏平行培训数据和计算资源的情况,反映了世界大多数语言和研究这些语言的研究人员的现实情况。我们提出了一个简单且可扩展的方法来改进未经监督的NMT,表明如何用双语字典加上少量的额外计算资源来训练模型,从而大大提高其性能。我们还展示了如何使用字典来编码转换单语数据以创造更可比的数据,可以进一步提高绩效。由于监督不力,我们的最佳方法取得了BLEU分数,从而改善了对英文$\rightrow$Gujarati(+18.88)、英元\rightrowal$Kazakh(+5.84)和英元\right$Somali(+1.16)的监督结果,从而显示了低资源配置资源许多低资源语言的超强NMT(+1.16)的许诺。我们最了解的是,我们的工作是首次量化地展示了低资源中低资源配置资源的影响。