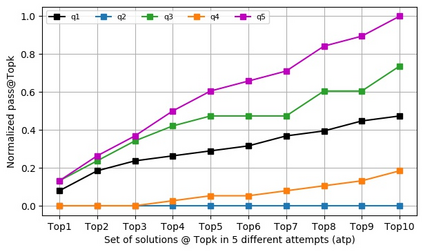
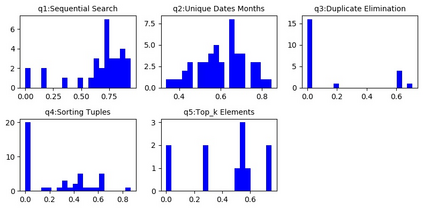
Automatic program synthesis is a long-lasting dream in software engineering. Recently, a promising Deep Learning (DL) based solution, called Copilot, has been proposed by Open AI and Microsoft as an industrial product. Although some studies evaluate the correctness of Copilot solutions and report its issues, more empirical evaluations are necessary to understand how developers can benefit from it effectively. In this paper, we study the capabilities of Copilot in two different programming tasks: (1) generating (and reproducing) correct and efficient solutions for fundamental algorithmic problems, and (2) comparing Copilot's proposed solutions with those of human programmers on a set of programming tasks. For the former, we assess the performance and functionality of Copilot in solving selected fundamental problems in computer science, like sorting and implementing basic data structures. In the latter, a dataset of programming problems with human-provided solutions is used. The results show that Copilot is capable of providing solutions for almost all fundamental algorithmic problems, however, some solutions are buggy and non-reproducible. Moreover, Copilot has some difficulties in combining multiple methods to generate a solution. Comparing Copilot to humans, our results show that the correct ratio of human solutions is greater than Copilot's correct ratio, while the buggy solutions generated by Copilot require less effort to be repaired. While Copilot shows limitations as an assistant for developers especially in advanced programming tasks, as highlighted in this study and previous ones, it can generate preliminary solutions for basic programming tasks.
翻译:自动程序合成是软件工程中长期的梦想。 最近,开放AI 和 Microsoft 提出一个有希望的深学习(DL)解决方案,称为“共同试办 ” 。 尽管一些研究评估了共同试办解决方案的正确性并报告了其问题,但需要更多的实证评估,以了解开发者如何有效地从中受益。在本文中,我们研究共同试办在两种不同的方案编制任务中的能力:(1) 产生(和复制)正确和有效的基本算法问题解决方案,(2) 比较共同试办提出的解决方案与一套程序设计任务方面的人类程序设计员的拟议解决方案。对于前者,我们评估了共同试办在解决计算机科学中某些基本问题方面的绩效和功能,例如排序和实施基本数据结构。在后者中,需要使用一套与人类提供解决方案的方案编制问题有关的数据集。结果显示,共同试办能够为几乎所有基本算法问题提供解决方案,但有些解决方案是错误且不可否认的。 此外, 共同试办在将多种方法结合起来方面有一些困难。对于前者来说,我们评估了共同试办的绩效比,我们的结果表明,在模拟试办工作中的难度比更小。 而在试办的进度研究中则表明,在纠正模型中,对于人类解决方案的难度上,对于改进的难度比研究中, 的难度比是更小的难度比对改进的难度比是更小。