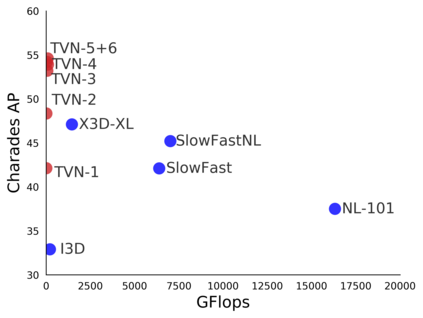
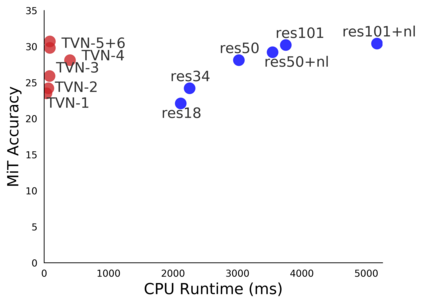
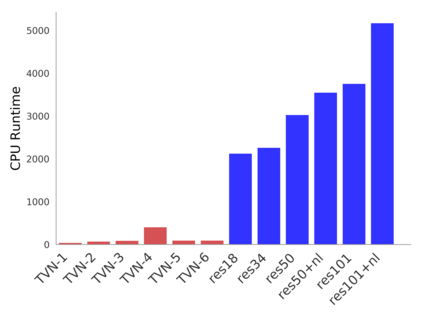
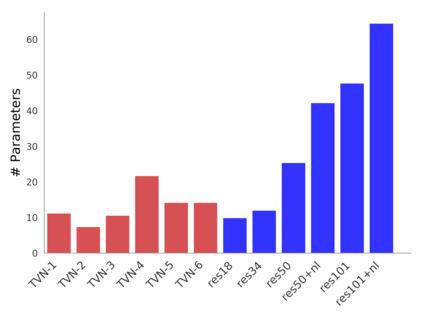
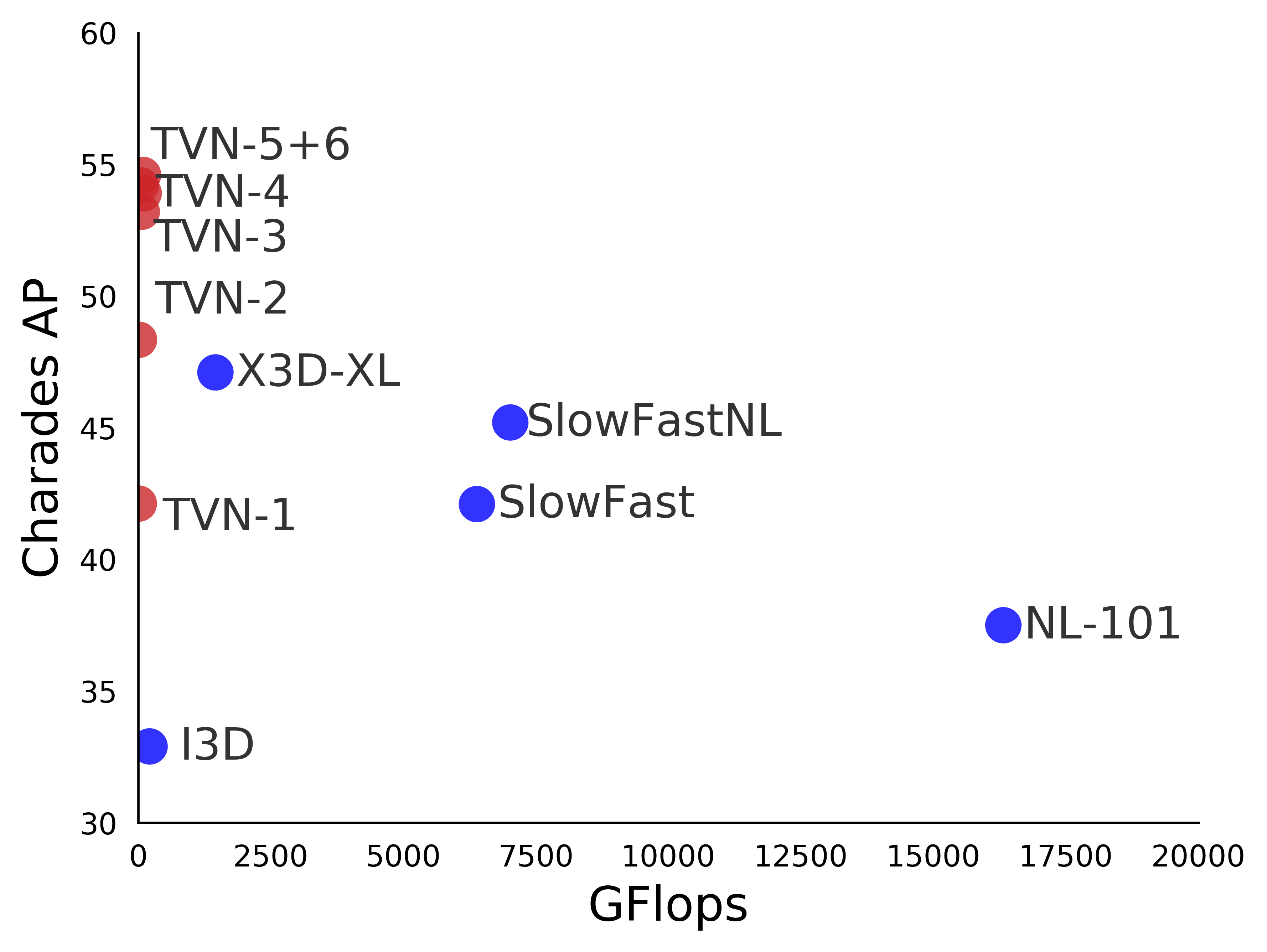
Video understanding is a challenging problem with great impact on the abilities of autonomous agents working in the real-world. Yet, solutions so far have been computationally intensive, with the fastest algorithms running for more than half a second per video snippet on powerful GPUs. We propose a novel idea on video architecture learning - Tiny Video Networks - which automatically designs highly efficient models for video understanding. The tiny video models run with competitive performance for as low as 37 milliseconds per video on a CPU and 10 milliseconds on a standard GPU.
翻译:视频理解是一个具有挑战性的问题,对在现实世界中工作的自主代理者的能力有着巨大影响。 然而,迄今为止,解决方案一直在计算上十分密集,最快的算法在强大的GPU上运行超过半秒钟的每个视频片段。 我们提出了一个关于视频结构学习的新理念 — — 微小视频网络 — — 自动设计高效视频理解模型。 小型视频模型具有竞争性性能,在CPU上每个视频可达37毫秒,在标准GPU上可达10毫秒。