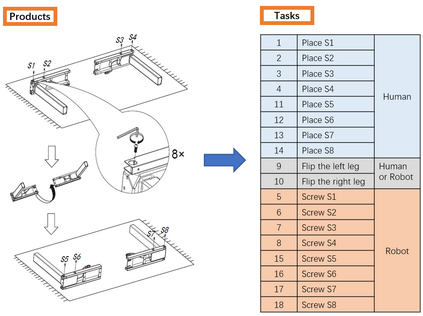
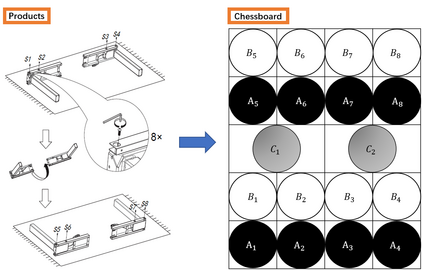
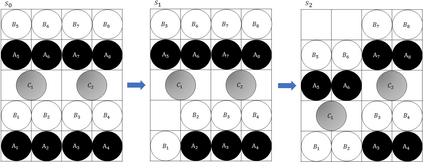
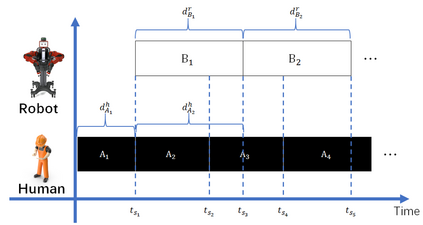
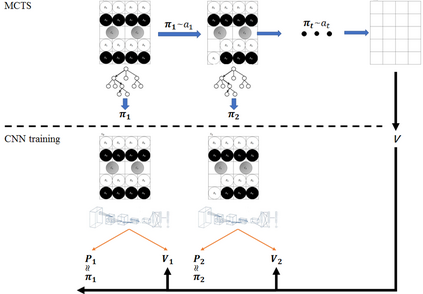
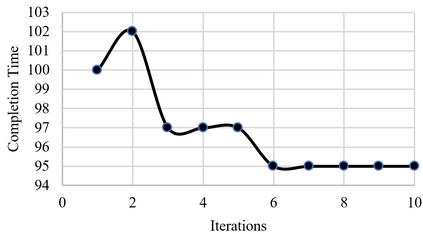
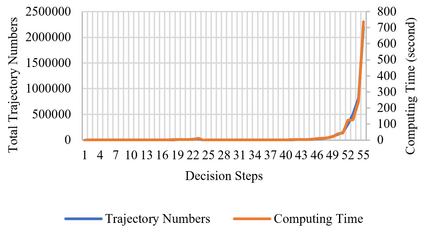
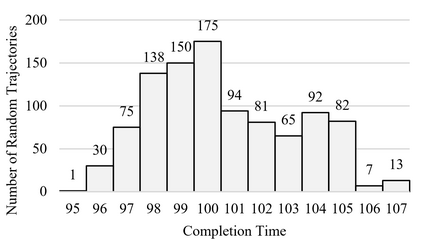
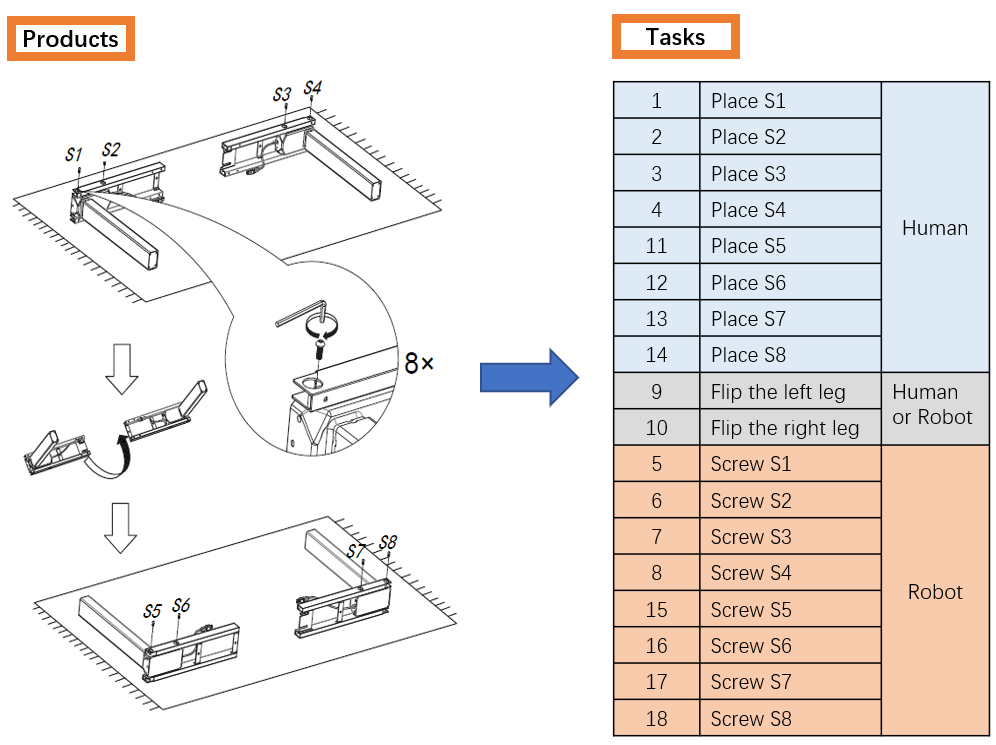
A long-standing goal of the Human-Robot Collaboration (HRC) in manufacturing systems is to increase the collaborative working efficiency. In line with the trend of Industry 4.0 to build up the smart manufacturing system, the Co-robot in the HRC system deserves better designing to be more self-organized and to find the superhuman proficiency by self-learning. Inspired by the impressive machine learning algorithms developed by Google Deep Mind like Alphago Zero, in this paper, the human-robot collaborative assembly working process is formatted into a chessboard and the selection of moves in the chessboard is used to analogize the decision making by both human and robot in the HRC assembly working process. To obtain the optimal policy of working sequence to maximize the working efficiency, the robot is trained with a self-play algorithm based on reinforcement learning, without guidance or domain knowledge beyond game rules. A neural network is also trained to predict the distribution of the priority of move selections and whether a working sequence is the one resulting in the maximum of the HRC efficiency. An adjustable desk assembly is used to demonstrate the proposed HRC assembly algorithm and its efficiency.
翻译:在制造系统中,人类机器人协作机制(HRC)的长期目标是提高协作工作效率。根据工业4.0建立智能制造系统的趋势,人权理事会系统中的Co-robot值得更好地设计,以便更自我组织,通过自我学习找到超人熟练程度。在谷歌深智(Google Deep Mind)开发的令人印象深刻的机器学习算法(如阿尔法戈佐罗)的启发下,本文件将人类机器人协作组装工作编成一个棋盘,在棋盘中选择动作用于模拟人类和机器人在人权理事会组装工作过程中的决策。为了获得工作顺序的最佳政策,以最大限度地提高工作效率,机器人接受基于强化学习的自我游戏算法培训,没有指导或超出游戏规则的域知识。神经网络还接受培训,以预测移动选择优先次序的分布以及工作序列是否达到人权理事会最高效率。可调整的桌面组装用于展示拟议的人权理事会组算法及其效率。