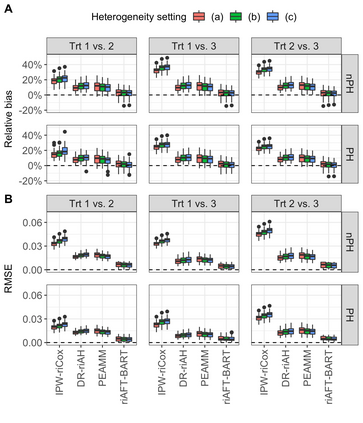
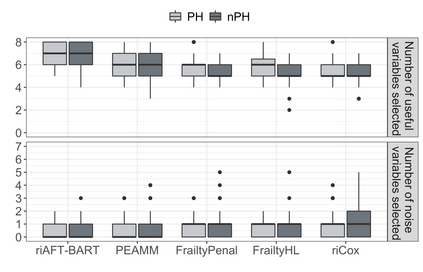
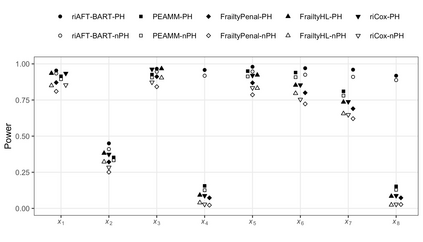
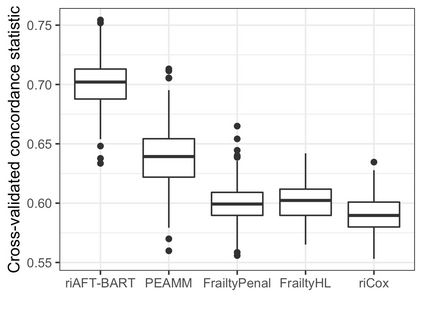
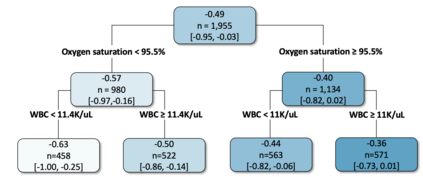
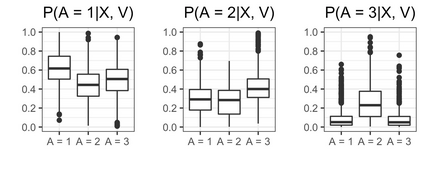
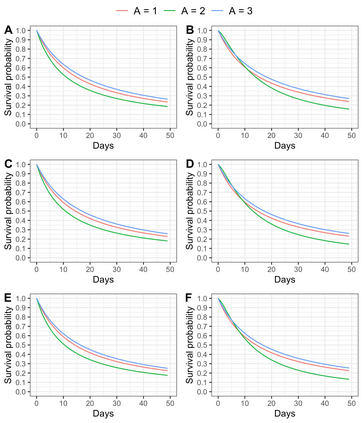
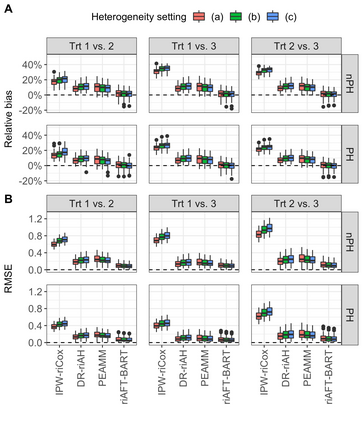
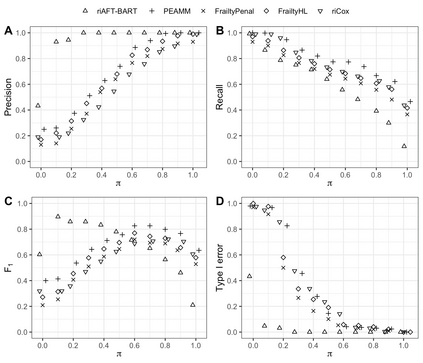
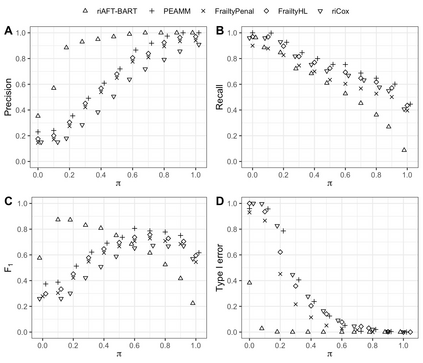
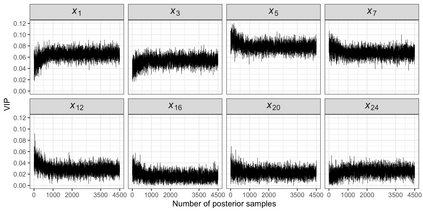
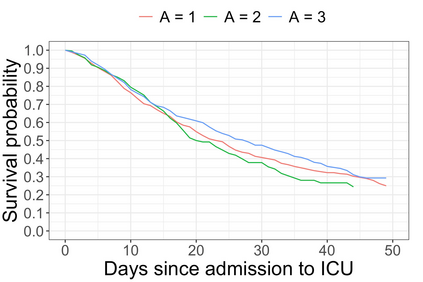
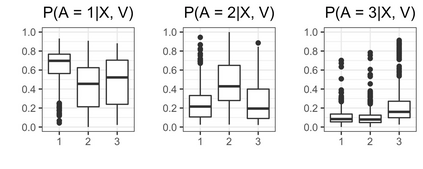
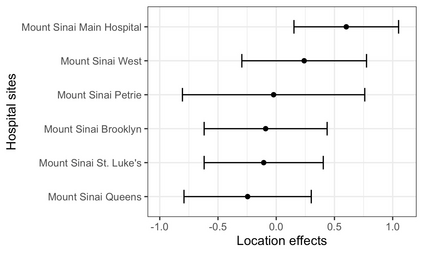
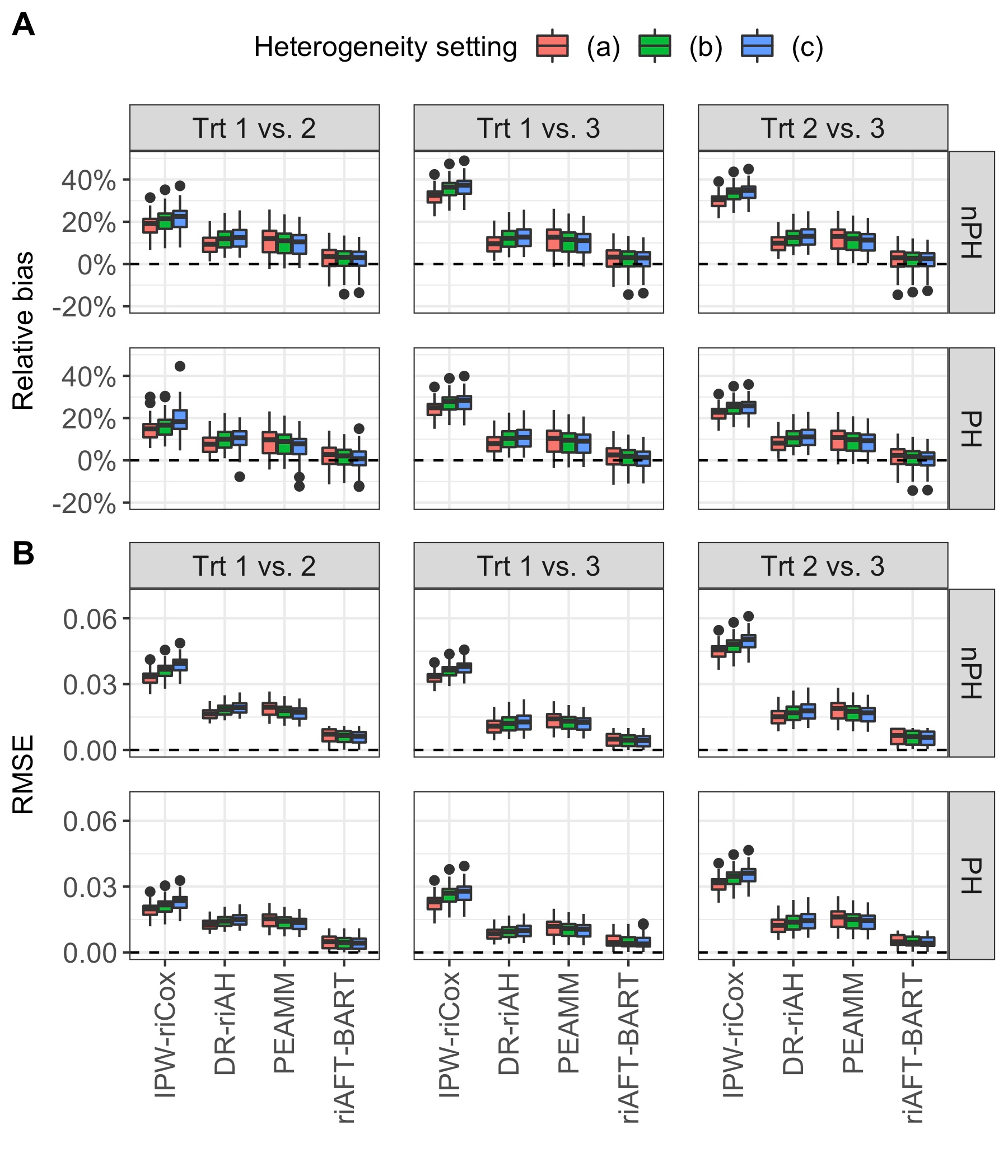
We recently developed a new method riAFT-BART to draw causal inferences about population treatment effect on patient survival from clustered and censored survival data while accounting for the multilevel data structure. The practical utility of this method goes beyond the estimation of population average treatment effect. In this work, we exposit how riAFT-BART can be used to solve two important statistical questions with clustered survival data: estimating the treatment effect heterogeneity and variable selection. Leveraging the likelihood-based machine learning, we describe a way in which we can draw posterior samples of the individual survival treatment effect from riAFT-BART model runs, and use the drawn posterior samples to perform an exploratory treatment effect heterogeneity analysis to identify subpopulations who may experience differential treatment effects than population average effects. There is sparse literature on methods for variable selection among clustered and censored survival data, particularly ones using flexible modeling techniques. We propose a permutation based approach using the predictor's variable inclusion proportion supplied by the riAFT-BART model for variable selection. To address the missing data issue frequently encountered in health databases, we propose a strategy to combine bootstrap imputation and riAFT-BART for variable selection among incomplete clustered survival data. We conduct an expansive simulation study to examine the practical operating characteristics of our proposed methods. Finally, we demonstrate the methods via a case study of predictors for in-hospital mortality among severe COVID-19 patients and estimating the heterogeneous treatment effects of three COVID-specific medications. The methods developed in this work are readily available in the $\R$ package $\textsf{riAFTBART}$.
翻译:暂无翻译