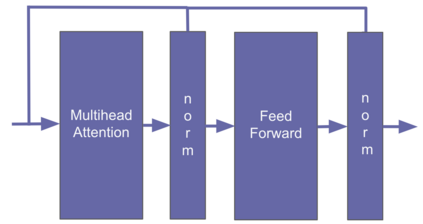
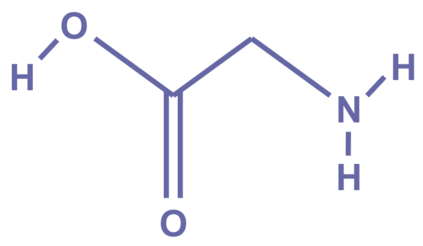
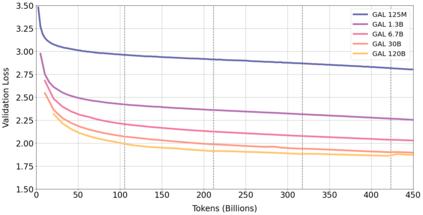
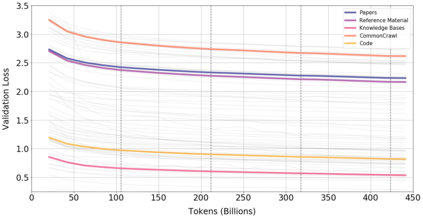
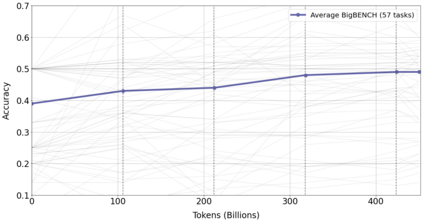
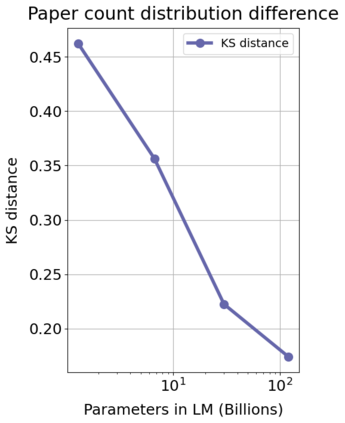
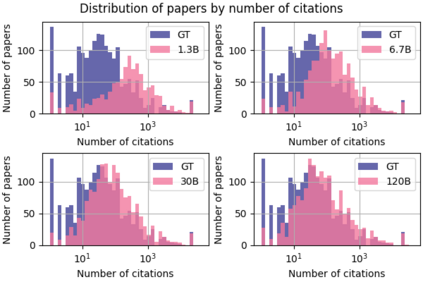
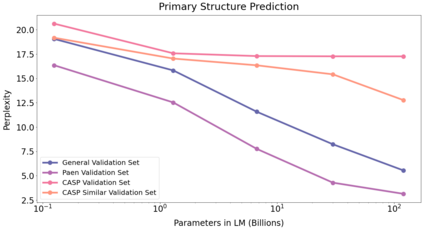
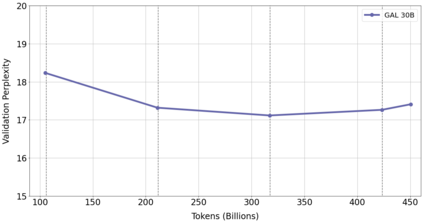
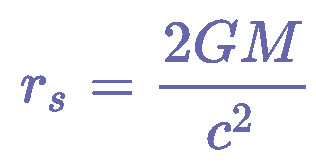Information overload is a major obstacle to scientific progress. The explosive growth in scientific literature and data has made it ever harder to discover useful insights in a large mass of information. Today scientific knowledge is accessed through search engines, but they are unable to organize scientific knowledge alone. In this paper we introduce Galactica: a large language model that can store, combine and reason about scientific knowledge. We train on a large scientific corpus of papers, reference material, knowledge bases and many other sources. We outperform existing models on a range of scientific tasks. On technical knowledge probes such as LaTeX equations, Galactica outperforms the latest GPT-3 by 68.2% versus 49.0%. Galactica also performs well on reasoning, outperforming Chinchilla on mathematical MMLU by 41.3% to 35.7%, and PaLM 540B on MATH with a score of 20.4% versus 8.8%. It also sets a new state-of-the-art on downstream tasks such as PubMedQA and MedMCQA dev of 77.6% and 52.9%. And despite not being trained on a general corpus, Galactica outperforms BLOOM and OPT-175B on BIG-bench. We believe these results demonstrate the potential for language models as a new interface for science. We open source the model for the benefit of the scientific community.
翻译:科学文献和数据爆炸性增长使得在大量信息中发现有用见解更加困难。 今天,科学知识是通过搜索引擎获得的,但是它们无法单独组织科学知识。 在本文中,我们引入了卡拉狄加:一个大型语言模型,可以储存、结合和解释科学知识。我们用大量的论文、参考材料、知识基础和许多其他来源进行大量科学培训。我们在一系列科学任务方面比现有的模式要好。在诸如LaTeX等方程式、Galactica比最新的GPT-3高出68.2%比49.0%等技术知识探测器方面,Galactia也表现良好,在数学MMLU上比Chinchilla高41.3%比35.7%,在MATH上比Chinchilla高540B,分数为20.4%比8.8%。我们还在诸如PubMedQA和MedMCQA等低调77.6%和52.9 %的技术探索者。尽管卡拉狄加(Galactica)还未能在推理学方面进行良好的演练,在GLO-B的通用界面上展示。