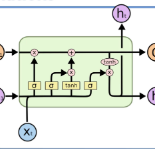
This paper presents a unified study of four distinct modeling approaches for classifying dysarthria severity in the Speech Analysis for Neurodegenerative Diseases (SAND) challenge. All models tackle the same five class classification task using a common dataset of speech recordings. We investigate: (1) a ViT-OF method leveraging a Vision Transformer on spectrogram images, (2) a 1D-CNN approach using eight 1-D CNN's with majority-vote fusion, (3) a BiLSTM-OF approach using nine BiLSTM models with majority vote fusion, and (4) a Hierarchical XGBoost ensemble that combines glottal and formant features through a two stage learning framework. Each method is described, and their performances on a validation set of 53 speakers are compared. Results show that while the feature-engineered XGBoost ensemble achieves the highest macro-F1 (0.86), the deep learning models (ViT, CNN, BiLSTM) attain competitive F1-scores (0.70) and offer complementary insights into the problem.
翻译:本文针对神经退行性疾病语音分析挑战中的构音障碍严重程度分类问题,对四种不同的建模方法进行了统一研究。所有模型均使用相同的语音录音数据集,处理相同的五分类任务。我们研究了:(1)ViT-OF方法,利用视觉Transformer处理频谱图图像;(2)1D-CNN方法,使用八个一维卷积神经网络结合多数投票融合;(3)BiLSTM-OF方法,采用九个双向长短期记忆网络结合多数投票融合;(4)分层XGBoost集成方法,通过两阶段学习框架结合声门和共振峰特征。详细描述了每种方法,并比较了它们在包含53名说话者的验证集上的性能。结果表明,虽然基于特征工程的XGBoost集成获得了最高的宏平均F1分数(0.86),但深度学习模型(ViT、CNN、BiLSTM)也取得了具有竞争力的F1分数(0.70),并为该问题提供了互补性的研究视角。