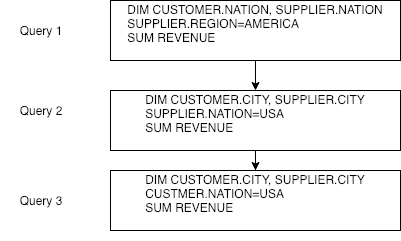
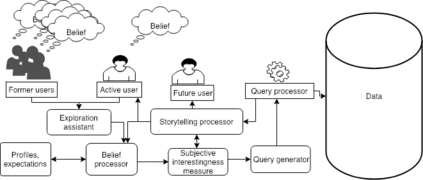
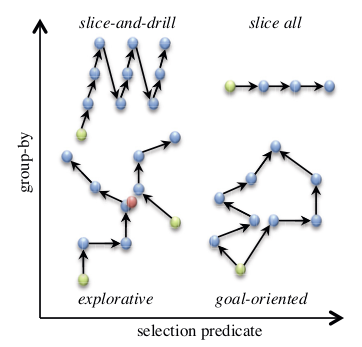
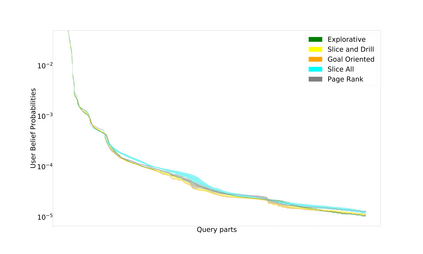
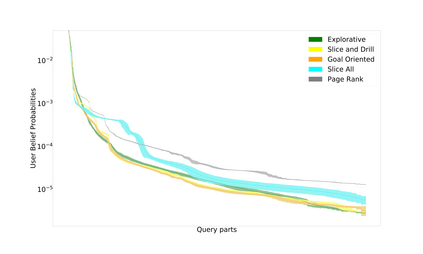
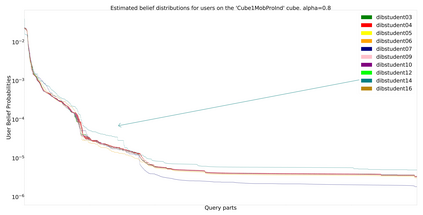
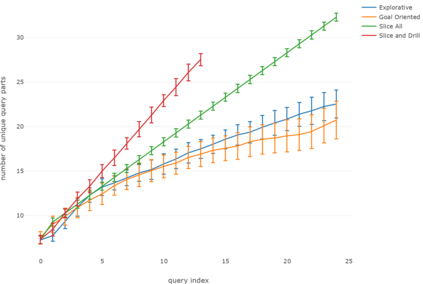
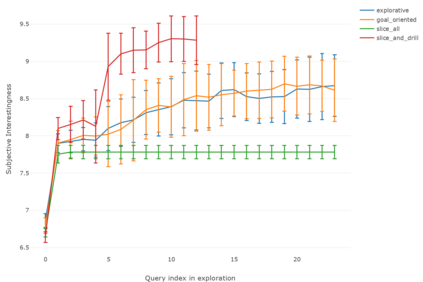
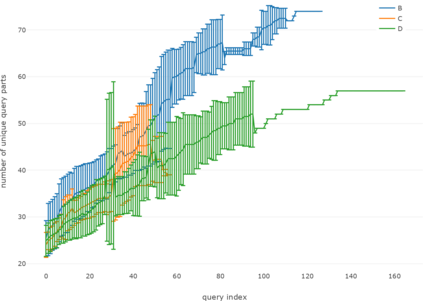
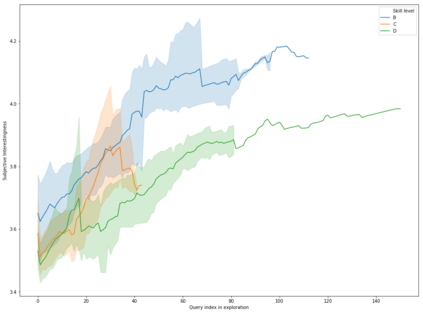
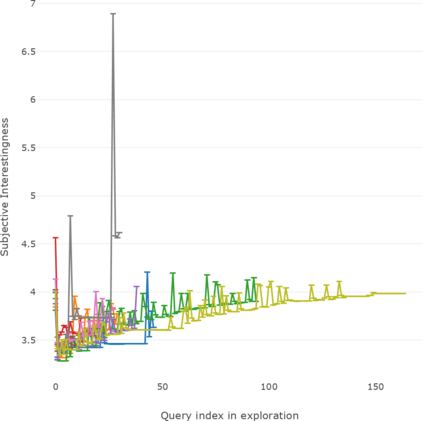
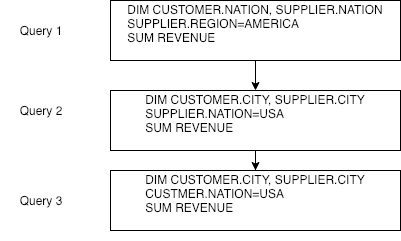
This paper addresses the problem of defining a subjective interestingness measure for BI exploration. Such a measure involves prior modeling of the belief of the user. The complexity of this problem lies in the impossibility to ask the user about the degree of belief in each element composing their knowledge prior to the writing of a query. To this aim, we propose to automatically infer this user belief based on the user's past interactions over a data cube, the cube schema and other users past activities. We express the belief under the form of a probability distribution over all the query parts potentially accessible to the user, and use a random walk to learn this distribution. This belief is then used to define a first Subjective Interestingness measure over multidimensional queries. Experiments conducted on simulated and real explorations show how this new subjective interestingness measure relates to prototypical and real user behaviors, and that query parts offer a reasonable proxy to infer user belief.
翻译:本文探讨为 BI 探索定义主观的有趣度量度的问题。 这样的度量涉及先对用户的信念进行建模。 这个问题的复杂性在于无法向用户询问在撰写查询之前构成其知识的每个要素的信念程度。 为此,我们提议根据用户过去对数据立方体、 立方体 和其他用户过去的活动的相互作用,自动推断用户的这种信念。 我们以对用户可能访问的所有查询部分的概率分布形式表达这种信念, 并使用随机行走来了解这种分布。 这个信念随后被用来界定第一个主观的取人度度度, 而不是多维查询。 模拟和真实探索实验显示这一新主观的有趣度度度度度度度度量与典型和实际用户行为的关系, 以及查询部分为推断用户的信念提供了合理的代理。