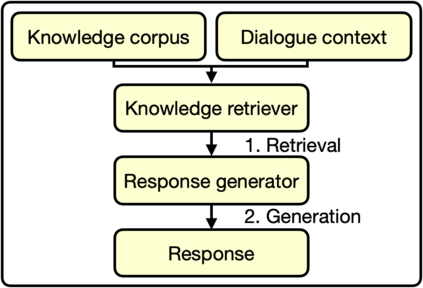
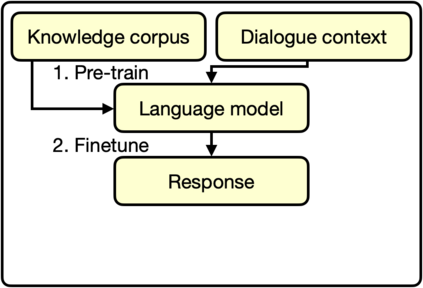
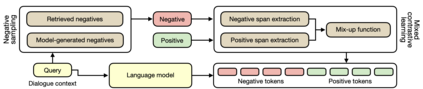
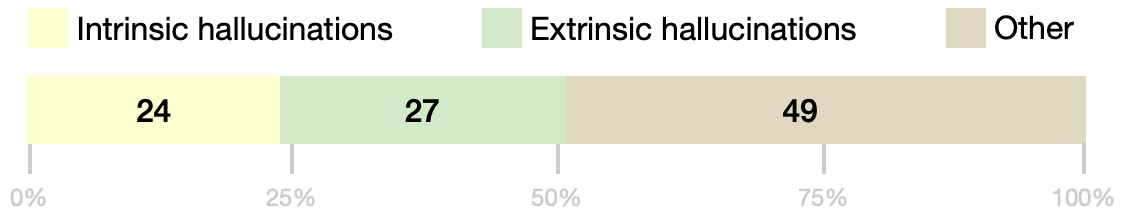Pre-trained language models (LMs) store knowledge in their parameters and can generate informative responses when used in conversational systems. However, LMs suffer from the problem of "hallucination:" they may generate plausible-looking statements that are irrelevant or factually incorrect. To address this problem, we propose a contrastive learning scheme, named MixCL. A novel mixed contrastive objective is proposed to explicitly optimize the implicit knowledge elicitation process of LMs, and thus reduce their hallucination in conversations. We also examine negative sampling strategies of retrieved hard negatives and model-generated negatives. We conduct experiments on Wizard-of-Wikipedia, a public, open-domain knowledge-grounded dialogue benchmark, and assess the effectiveness of MixCL. MixCL effectively reduces the hallucination of LMs in conversations and achieves the highest performance among LM-based dialogue agents in terms of relevancy and factuality. We show that MixCL achieves comparable performance to state-of-the-art KB-based approaches while enjoying notable advantages in terms of efficiency and scalability.
翻译:培训前语言模型(LMS)在其参数中储存知识,在对话系统使用时可以产生信息反应。然而,LMS却遇到“职业介绍:”问题,它们可能产生貌似合理的、不相干或事实不正确的言论。为了解决这一问题,我们提出了一个反比学习计划,名为MixCL。提出了一个新的混合对比性目标,以明确优化LMS的隐含知识获取过程,从而减少谈话中的幻觉。我们还审查了检索到的硬底片和模型产生的底片的负面抽样战略。我们进行了关于Wikipedia的负面抽样战略的实验,这是一个公开的开放的基于知识的对话基准,并评估MixCLS的有效性。MixCL有效地降低了LMs在对话中的幻觉,并在相关性和事实质量方面实现了基于LM对话的代理人的最高绩效。我们表明,MixCL在效率和可扩展性方面享有显著的优势。