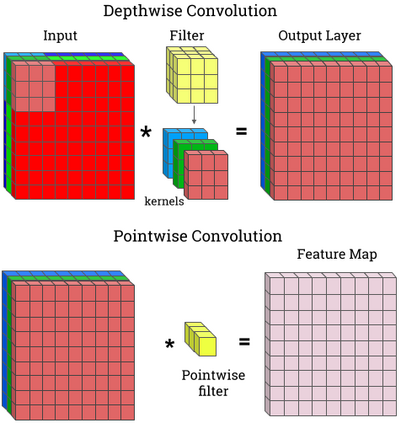
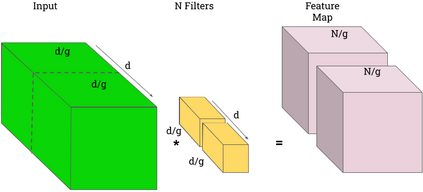
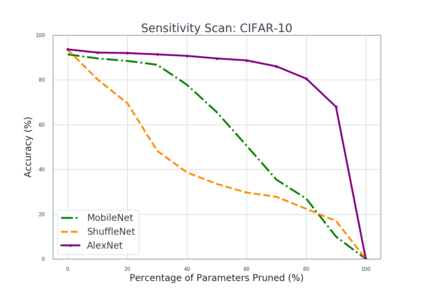
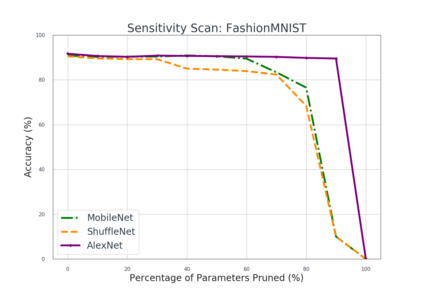
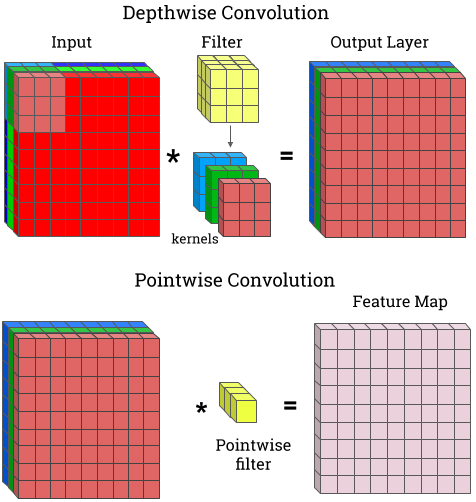
Deep neural networks are typically too computationally expensive to run in real-time on consumer-grade hardware and low-powered devices. In this paper, we investigate reducing the computational and memory requirements of neural networks through network pruning and quantisation. We examine their efficacy on large networks like AlexNet compared to recent compact architectures: ShuffleNet and MobileNet. Our results show that pruning and quantisation compresses these networks to less than half their original size and improves their efficiency, particularly on MobileNet with a 7x speedup. We also demonstrate that pruning, in addition to reducing the number of parameters in a network, can aid in the correction of overfitting.
翻译:深神经网络通常在计算上过于昂贵,无法实时运行消费级硬件和低功率设备。 在本文中,我们通过网络运行和量化调查减少神经网络的计算和内存要求。我们对照最近的紧凑结构(ShuffleNet 和 MobileNet ), 审视了亚历克斯Net 等大型网络的功效。我们的结果表明,运行和量化将这些网络压缩到不到其最初规模的一半,提高了其效率,特别是移动网络的效能,并加速了7x速度。我们还表明,除了减少网络参数的数量外,运行和量化还能帮助校正超装。