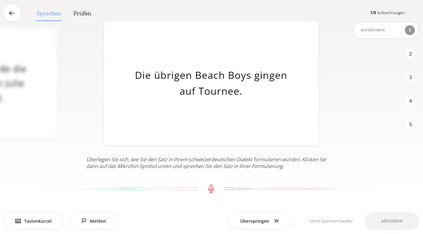
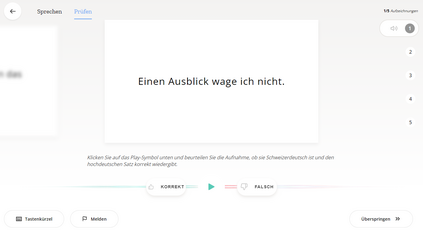
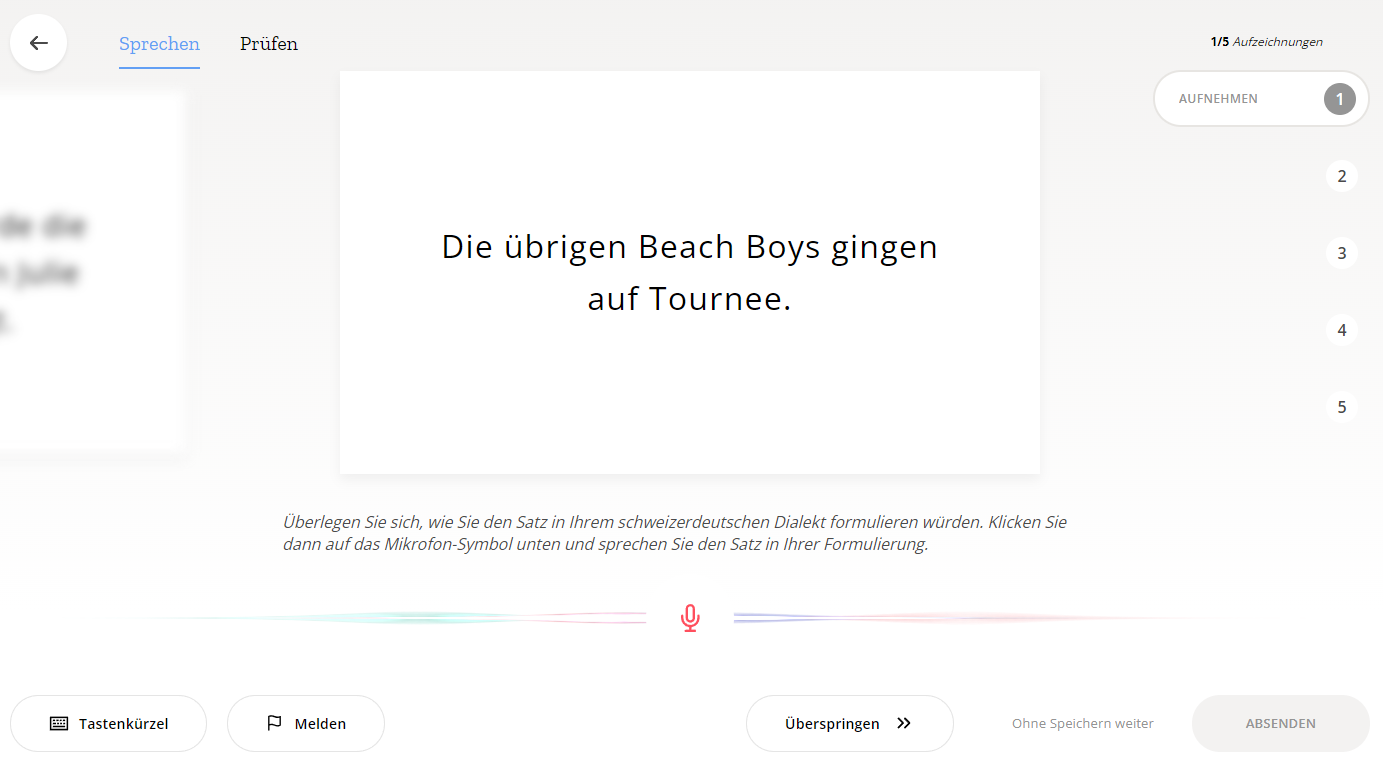
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.
翻译:我们提供瑞士德语方言SDS-200,这是一套瑞士德语方言,附有标准德语译文,并附有讲者方言、年龄和性别信息的瑞士德语方言译文,该数据集允许培训语言翻译、方言识别和语音合成系统等。这些数据是使用向公众开放的网络记录工具收集的。每个参与者都获得德文标准文本,并被要求将其翻译为瑞士德语方言,然后才予以记录。为提高方言质量,其他参与者对录音进行了验证。数据包括大约4 000名不同发言者的200小时发言,涵盖了瑞士-德国方言的很大一部分。我们发布SDS-200,同时推出一个基线语音翻译模型,该模型在SDS-200测试集上达到30.3字差率和53.1比特列伊分。此外,我们使用SDS-200微调用预先训练的XLS-R模型进行微调,实现21.6WER和64.0比欧。