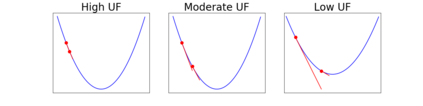
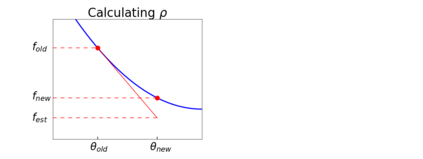
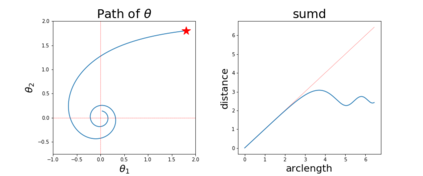
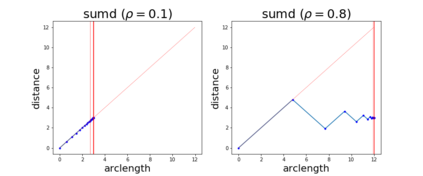
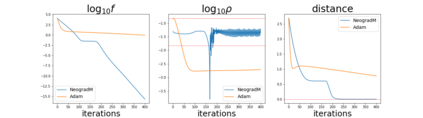
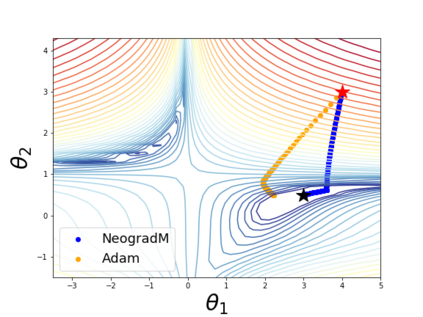
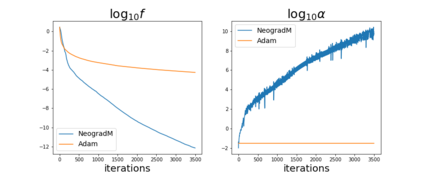
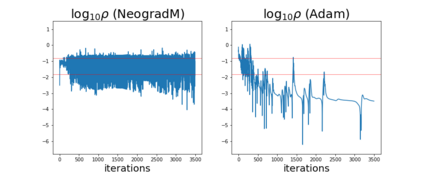
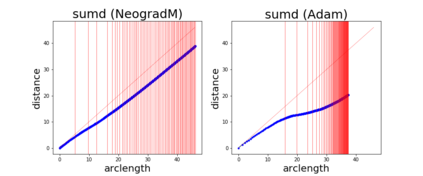
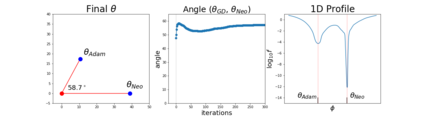
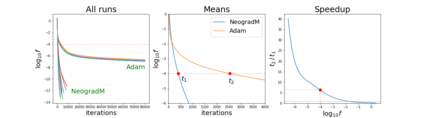
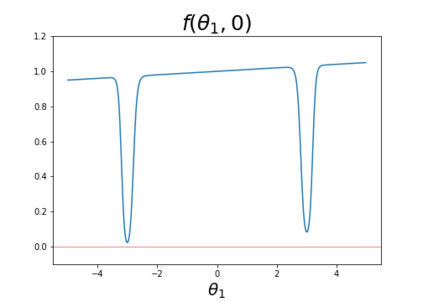
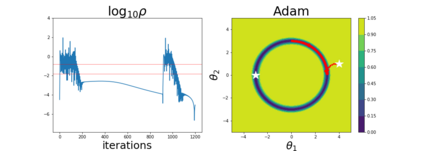
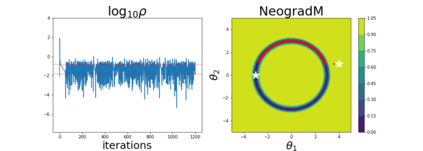
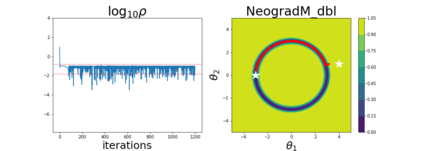
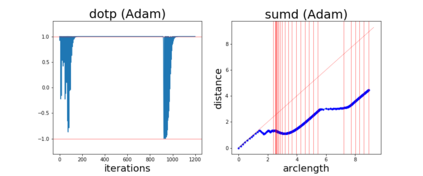
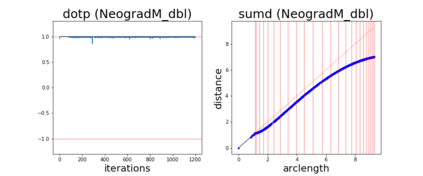
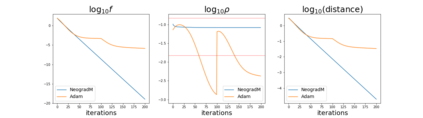
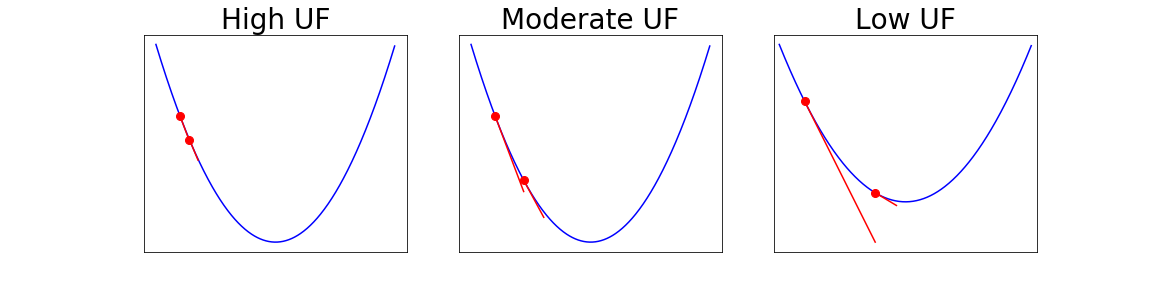
Since its inception by Cauchy in 1847, the gradient descent algorithm has been without guidance as to how to efficiently set the learning rate. This paper identifies a concept, defines metrics, and introduces algorithms to provide such guidance. The result is a family of algorithms (Neograd) based on a {\em constant $\rho$ ansatz}, where $\rho$ is a metric based on the error of the updates. This allows one to adjust the learning rate at each step, using a formulaic estimate based on $\rho$. It is now no longer necessary to do trial runs beforehand to estimate a single learning rate for an entire optimization run. The additional costs to operate this metric are trivial. One member of this family of algorithms, NeogradM, can quickly reach much lower cost function values than other first order algorithms. Comparisons are made mainly between NeogradM and Adam on an array of test functions and on a neural network model for identifying hand-written digits. The results show great performance improvements with NeogradM.
翻译:Cauchy于1847年启用了梯度下降算法,但自该算法以来,在如何有效设定学习率方面一直没有指导。本文确定了一个概念,定义了衡量标准,并引入了算法来提供这种指导。结果产生了一个基于 $$\rho$ ansatz} 的算法(Neograd) 的组合(Neograd), 这个组合的成本值比其他一阶算法要低得多。 比较主要是NegradM和Adam在一系列测试功能上和在确定手写数字的神经网络模型上进行的。 结果显示与NeogradM的显著性能改进。