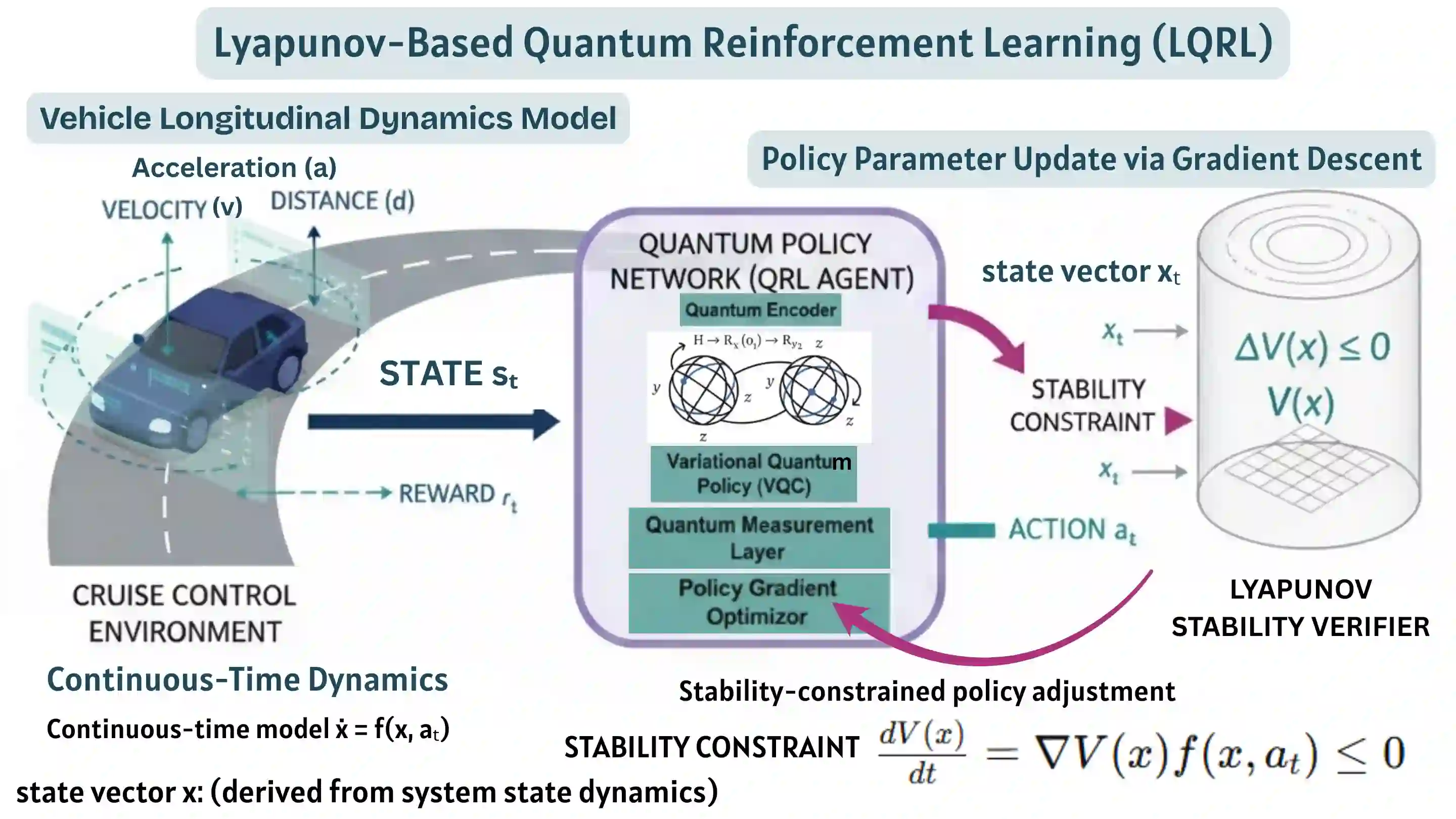
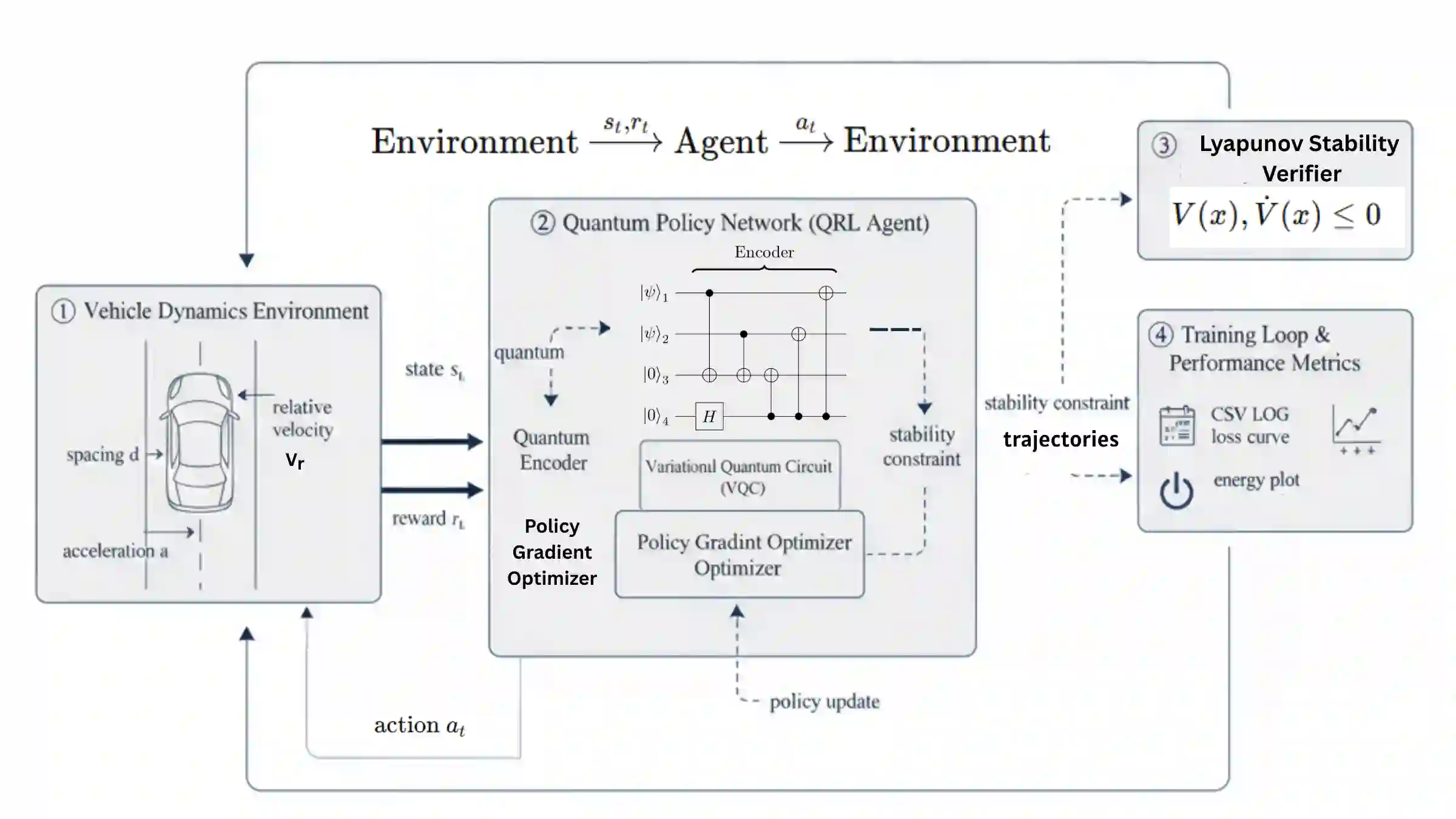
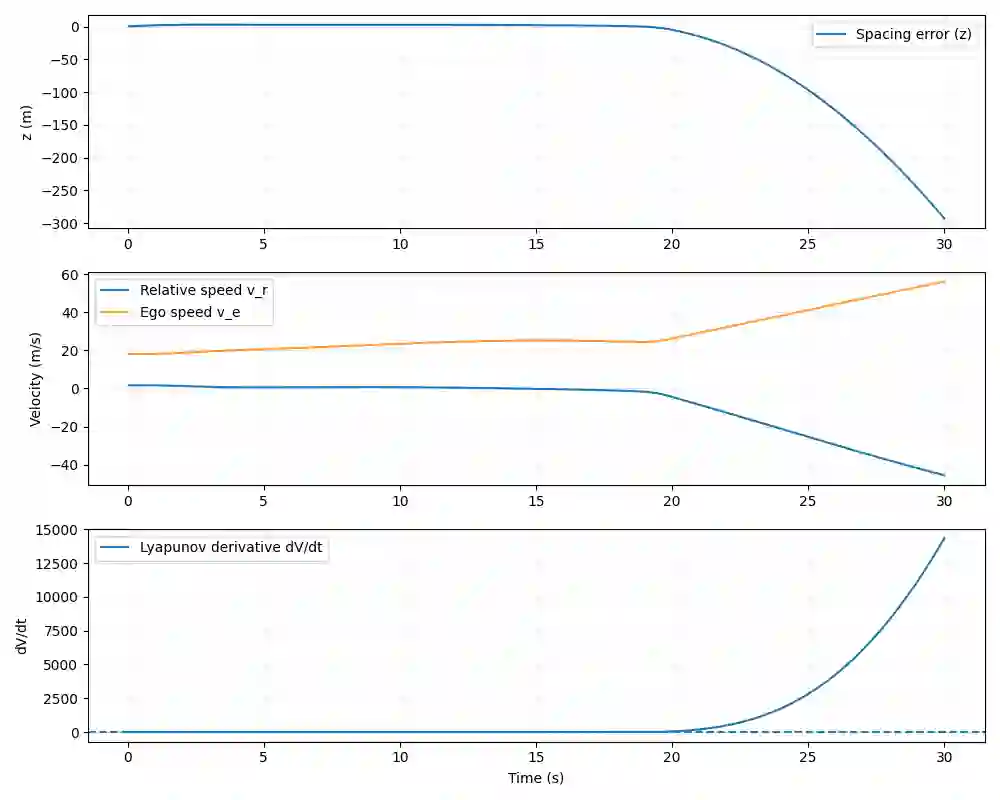
This paper presents a novel Lyapunov-Based Quantum Reinforcement Learning (LQRL) framework that integrates quantum policy optimization with Lyapunov stability analysis for continuous-time vehicle control. The proposed approach combines the representational power of variational quantum circuits (VQCs) with a stability-aware policy gradient mechanism to ensure asymptotic convergence and safe decision-making under dynamic environments. The vehicle longitudinal control problem was formulated as a continuous-state reinforcement learning task, where the quantum policy network generates control actions subject to Lyapunov stability constraints. Simulation experiments were conducted in a closed-loop adaptive cruise control scenario using a quantum-inspired policy trained under stability feedback. The results demonstrate that the LQRL framework successfully embeds Lyapunov stability verification into quantum policy learning, enabling interpretable and stability-aware control performance. Although transient overshoot and Lyapunov divergence were observed under aggressive acceleration, the system maintained bounded state evolution, validating the feasibility of integrating safety guarantees within quantum reinforcement learning architectures. The proposed framework provides a foundational step toward provably safe quantum control in autonomous systems and hybrid quantum-classical optimization domains.
翻译:本文提出了一种新颖的基于李雅普诺夫稳定性的量子强化学习框架,该框架将量子策略优化与李雅普诺夫稳定性分析相结合,用于连续时间车辆控制。所提出的方法结合了变分量子线路的表达能力与稳定性感知的策略梯度机制,以确保在动态环境下的渐近收敛和安全决策。车辆纵向控制问题被构建为一个连续状态强化学习任务,其中量子策略网络在满足李雅普诺夫稳定性约束的条件下生成控制动作。仿真实验在一个闭环自适应巡航控制场景中进行,使用了在稳定性反馈下训练的量子启发式策略。结果表明,LQRL框架成功地将李雅普诺夫稳定性验证嵌入到量子策略学习中,实现了可解释且具有稳定性感知的控制性能。虽然在激进加速条件下观察到瞬态超调和李雅普诺夫函数发散,但系统保持了有界状态演化,验证了在量子强化学习架构中集成安全性保证的可行性。所提出的框架为在自主系统和混合量子-经典优化领域中实现可证明安全的量子控制奠定了初步基础。