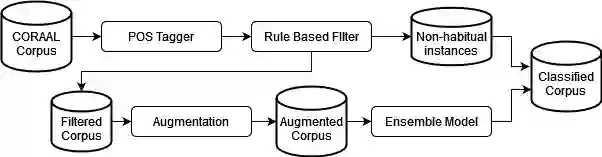
Recent research has highlighted that natural language processing (NLP) systems exhibit a bias against African American speakers. The bias errors are often caused by poor representation of linguistic features unique to African American English (AAE), due to the relatively low probability of occurrence of many such features in training data. We present a workflow to overcome such bias in the case of habitual "be". Habitual "be" is isomorphic, and therefore ambiguous, with other forms of "be" found in both AAE and other varieties of English. This creates a clear challenge for bias in NLP technologies. To overcome the scarcity, we employ a combination of rule-based filters and data augmentation that generate a corpus balanced between habitual and non-habitual instances. With this balanced corpus, we train unbiased machine learning classifiers, as demonstrated on a corpus of AAE transcribed texts, achieving .65 F$_1$ score disambiguating habitual "be".
翻译:最近的研究突出表明,自然语言处理系统(NLP)对讲非洲语言的人有偏见,偏差错误往往是由于在培训数据中出现许多这类特征的概率相对较低而造成,因为非裔美国人英语语言特征的描述不甚清晰,我们提出了一个工作流程,以克服习惯“be”中的这种偏差。习惯“be”是无定型的,因此模糊不清,在AAE和其他类型的英语中都发现了其他形式的“be”。这给在NLP技术中的偏差带来了明显的挑战。为了克服这种偏差,我们采用了基于规则的过滤器和数据增强相结合的办法,在习惯和非习惯实例之间形成了一种平衡的主体。有了这种平衡,我们培训了不带偏见的机器学习分类人员,如AE转录的文本文集所显示的那样,我们培训了无偏见的机器学习分类人员,达到65F$_1美元分的比分不协调的习惯“be”。