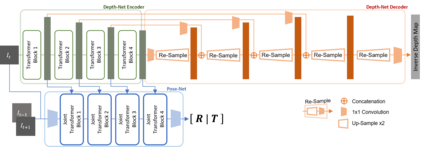
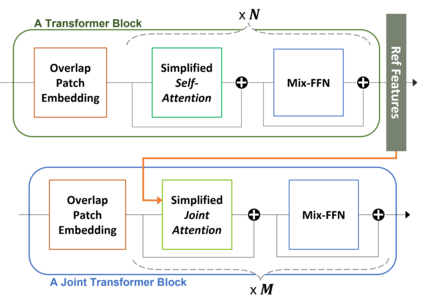
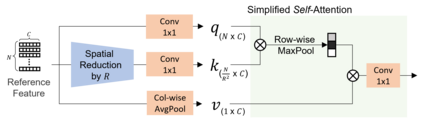
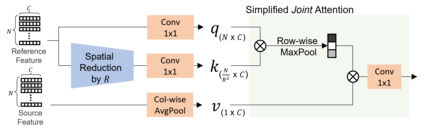
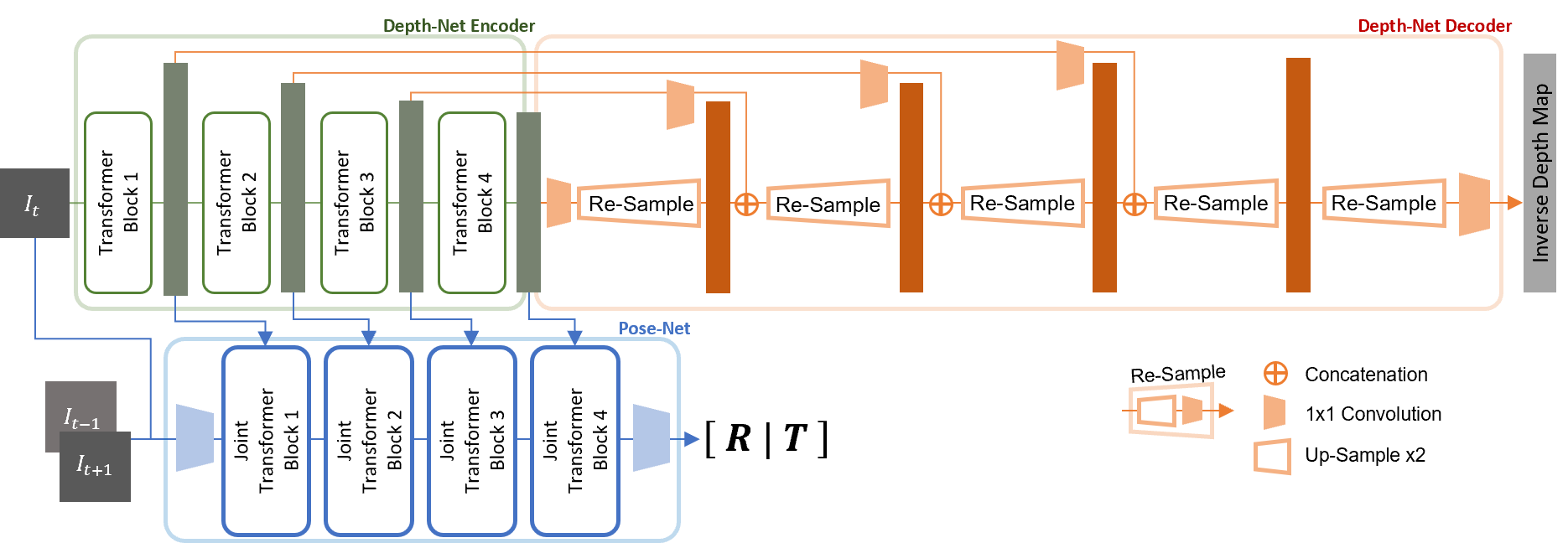
Transformer and its variants have shown state-of-the-art results in many vision tasks recently, ranging from image classification to dense prediction. Despite of their success, limited work has been reported on improving the model efficiency for deployment in latency-critical applications, such as autonomous driving and robotic navigation. In this paper, we aim at improving upon the existing transformers in vision, and propose a method for self-supervised monocular Depth Estimation with Simplified Transformer (DEST), which is efficient and particularly suitable for deployment on GPU-based platforms. Through strategic design choices, our model leads to significant reduction in model size, complexity, as well as inference latency, while achieving superior accuracy as compared to state-of-the-art. We also show that our design generalize well to other dense prediction task without bells and whistles.
翻译:最近,从图像分类到密集预测等许多愿景任务中,变异器及其变异器都展示了最新最先进的结果。尽管取得了成功,但据报告,在提高部署潜伏关键应用程序(如自主驾驶和机器人导航)的模型效率方面,我们的工作有限。 在本文中,我们的目标是改进现有变压器的视觉功能,并提议一种使用简化变压器进行自我监督的单眼深度估计的方法,这种方法既高效又特别适合在基于 GPU 的平台上部署。通过战略设计选择,我们的模型导致模型大小、复杂性和推导延率大幅降低,同时实现与最新技术相比更高的准确性。我们还表明,我们的设计在没有钟声和哨声的情况下将其他密集的预测任务概括化。