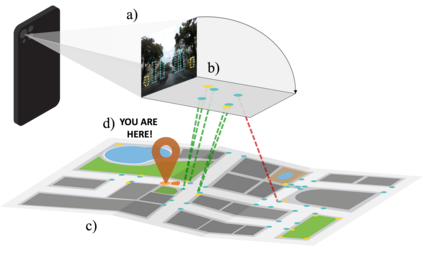
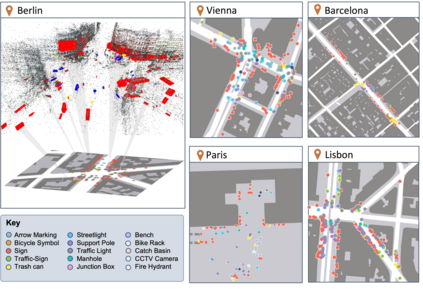
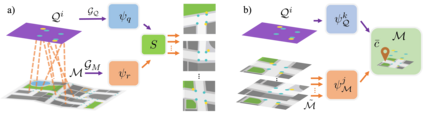
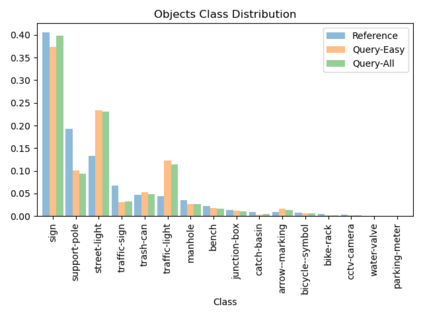
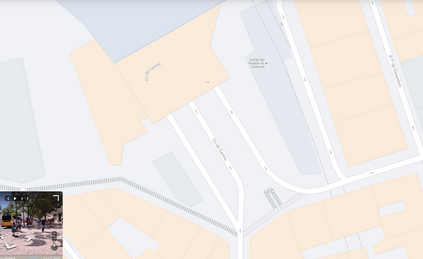
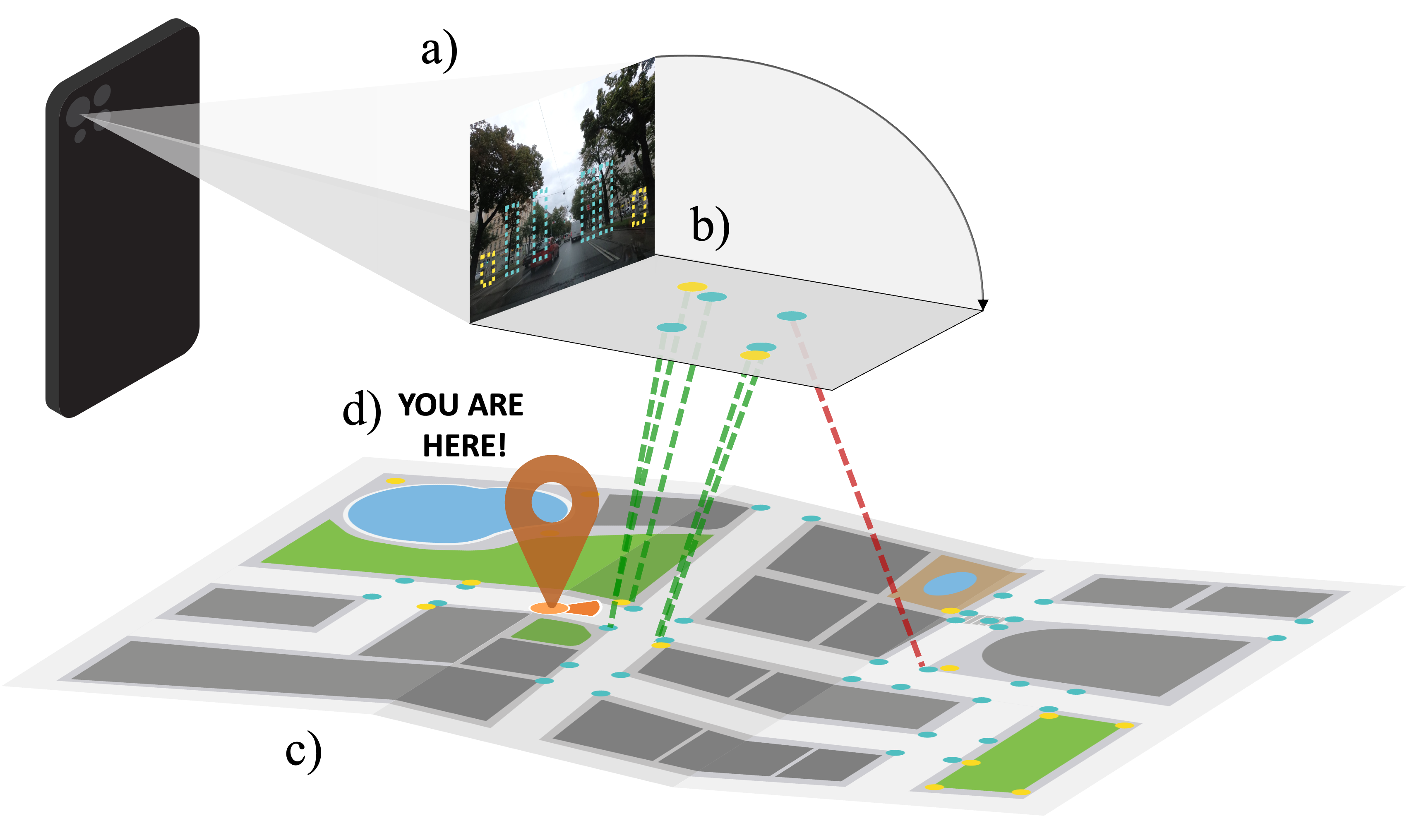
We introduce Flatlandia, a novel problem for visual localization of an image from object detections composed of two specific tasks: i) Coarse Map Localization: localizing a single image observing a set of objects in respect to a 2D map of object landmarks; ii) Fine-grained 3DoF Localization: estimating latitude, longitude, and orientation of the image within a 2D map. Solutions for these new tasks exploit the wide availability of open urban maps annotated with GPS locations of common objects (\eg via surveying or crowd-sourced). Such maps are also more storage-friendly than standard large-scale 3D models often used in visual localization while additionally being privacy-preserving. As existing datasets are unsuited for the proposed problem, we provide the Flatlandia dataset, designed for 3DoF visual localization in multiple urban settings and based on crowd-sourced data from five European cities. We use the Flatlandia dataset to validate the complexity of the proposed tasks.
翻译:我们引入了Flatlandia,一个新的问题,用于从由两个特定任务组成的对象检测中的单个图像进行视觉定位:i)粗略的地图定位:将观察到的一组对象与对象地标的2D地图相匹配;ii)细粒度3DoF定位:在2D地图中估计图像的纬度、经度和方向。解决这些新任务利用了大量提供了标注有常见对象GPS位置的城市开放地图(例如通过测量或众包)的存在。与通常用于视觉定位的大规模3D模型相比,这样的地图也更节约存储空间,同时还保护隐私。由于现有数据集不适用于所提出的问题,我们提供了Flatlandia数据集,设计用于在多个欧洲城市的城市环境中进行3DoF视觉定位,并基于众包数据。我们使用Flatlandia数据集来验证所提出任务的复杂度。