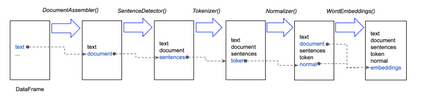
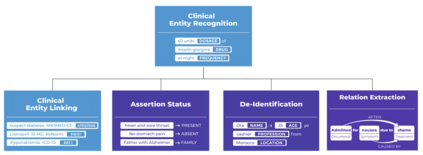
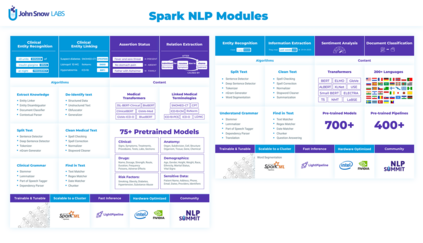
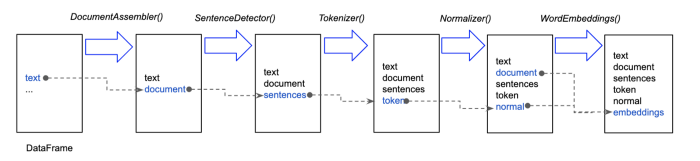
Spark NLP is a Natural Language Processing (NLP) library built on top of Apache Spark ML. It provides simple, performant and accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment. Spark NLP comes with 1100 pre trained pipelines and models in more than 192 languages. It supports nearly all the NLP tasks and modules that can be used seamlessly in a cluster. Downloaded more than 2.7 million times and experiencing nine times growth since January 2020, Spark NLP is used by 54% of healthcare organizations as the worlds most widely used NLP library in the enterprise.
翻译:Spark NLP是建立在Apache Spark ML之上的自然语言处理(NLP)图书馆。 它为在分布环境中容易扩展的机器学习管道提供简单、性能和准确的NLP说明。 Spark NLP提供1100个预先培训的管道和模型,其语言超过192种。 它支持几乎所有NLP的任务和模块,可在一个集群中无缝使用。 自2020年1月以来下载270万次以上,增长9倍。 54%的医疗保健组织将Spark NLP用作企业中最广泛使用NLP图书馆的世界。