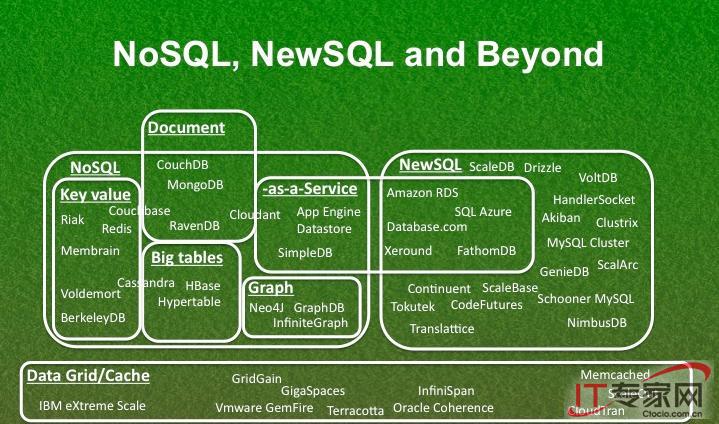
The success of SQL, NoSQL, and NewSQL databases is a reflection of their ability to provide significant functionality and performance benefits for specific domains, such as financial transactions, internet search, and data analysis. The BigDAWG polystore seeks to provide a mechanism to allow applications to transparently achieve the benefits of diverse databases while insulating applications from the details of these databases. Associative arrays provide a common approach to the mathematics found in different databases: sets (SQL), graphs (NoSQL), and matrices (NewSQL). This work presents the SQL relational model in terms of associative arrays and identifies the key mathematical properties that are preserved within SQL. These properties include associativity, commutativity, distributivity, identities, annihilators, and inverses. Performance measurements on distributivity and associativity show the impact these properties can have on associative array operations. These results demonstrate that associative arrays could provide a mathematical model for polystores to optimize the exchange of data and execution queries.
翻译:SQL、 NoSQL、 NoSQL 和 NewSQL 数据库的成功反映了它们有能力为金融交易、互联网搜索和数据分析等特定领域提供重要的功能和性能效益。 BigDAWG 聚层试图提供一个机制,允许应用程序透明地实现不同数据库的惠益,同时从这些数据库的细节中隔绝应用程序。组合阵列为不同数据库中发现的数学提供了一种共同方法:数据集(SQL)、图表(NoSQL)和矩阵(NewSQL)。这项工作展示了SQL 关联阵列模型,并确定了在SQL内保存的关键数学属性。这些属性包括关联性、共通性、分散性、身份、聚合器和反向。关于分配和关联性的绩效测量显示这些属性对组合阵列操作可能产生的影响。这些结果表明,组合阵列可以为组合提供数学模型,以优化数据交换和执行查询。