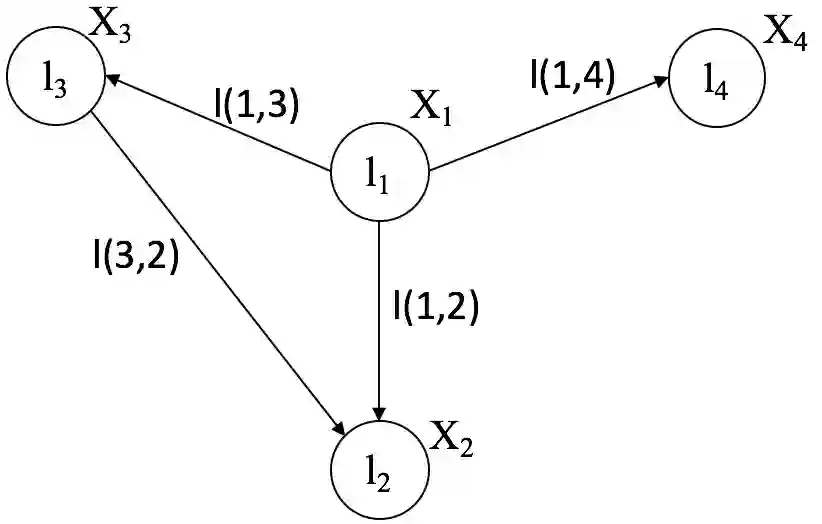
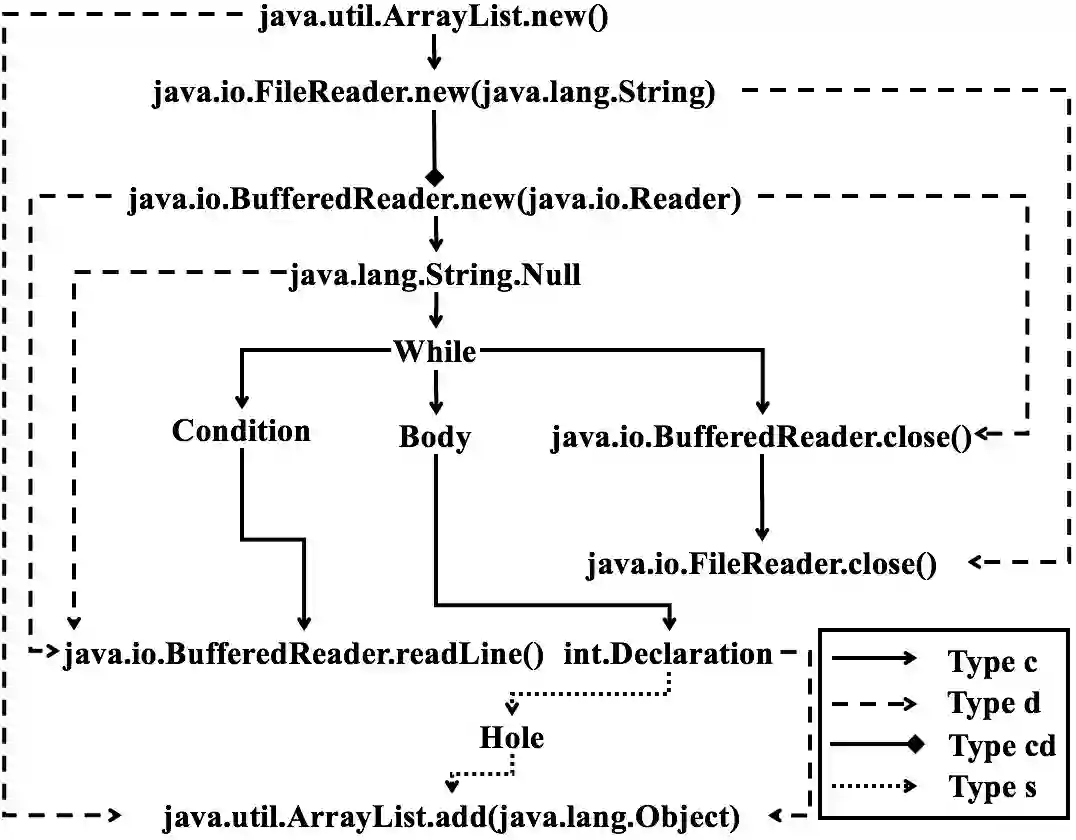
Context based API recommendation is an important way to help developers find the needed APIs effectively and efficiently. For effective API recommendation, we need not only a joint view of both structural and textual code information, but also a holistic view of correlated API usage in control and data flow graph as a whole. Unfortunately, existing API recommendation methods exploit structural or textual code information separately. In this work, we propose a novel API recommendation approach called APIRec-CST (API Recommendation by Combining Structural and Textual code information). APIRec-CST is a deep learning model that combines the API usage with the text information in the source code based on an API Context Graph Network and a Code Token Network that simultaneously learn structural and textual features for API recommendation. We apply APIRec-CST to train a model for JDK library based on 1,914 open-source Java projects and evaluate the accuracy and MRR (Mean Reciprocal Rank) of API recommendation with another 6 open-source projects. The results show that our approach achieves respectively a top-1, top-5, top-10 accuracy and MRR of 60.3%, 81.5%, 87.7% and 69.4%, and significantly outperforms an existing graph-based statistical approach and a tree-based deep learning approach for API recommendation. A further analysis shows that textual code information makes sense and improves the accuracy and MRR. We also conduct a user study in which two groups of students are asked to finish 6 programming tasks with or without our APIRec-CST plugin. The results show that APIRec-CST can help the students to finish the tasks faster and more accurately and the feedback on the usability is overwhelmingly positive.
翻译:基于背景的 API 建议是帮助开发者有效和高效地找到所需的 API 的重要方法。 为了有效 API 推荐, 我们不仅需要共同查看结构和文本代码信息, 还需要整体查看整个控制和数据流图中相关的 API 使用。 不幸的是, 现有的 API 推荐方法分别利用结构或文本代码信息。 在这项工作中, 我们提出一个新的 API 推荐方法, 称为 API 参考建议, 将结构和文本代码信息合并为 API 。 API 是一个深层次学习模式, 将 API 的用法与源代码中的文本信息结合起来, 基于 API 的 结构与文本代码信息, 以及基于 API 的源码信息信息信息信息, 以及基于 API 的源码和MRRR 代码, 我们采用的方法可以分别实现头1级、前5级、上级和MRRU的文本信息, 以60.3%的源码为基础完成 A.