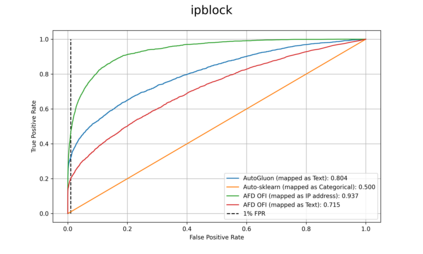
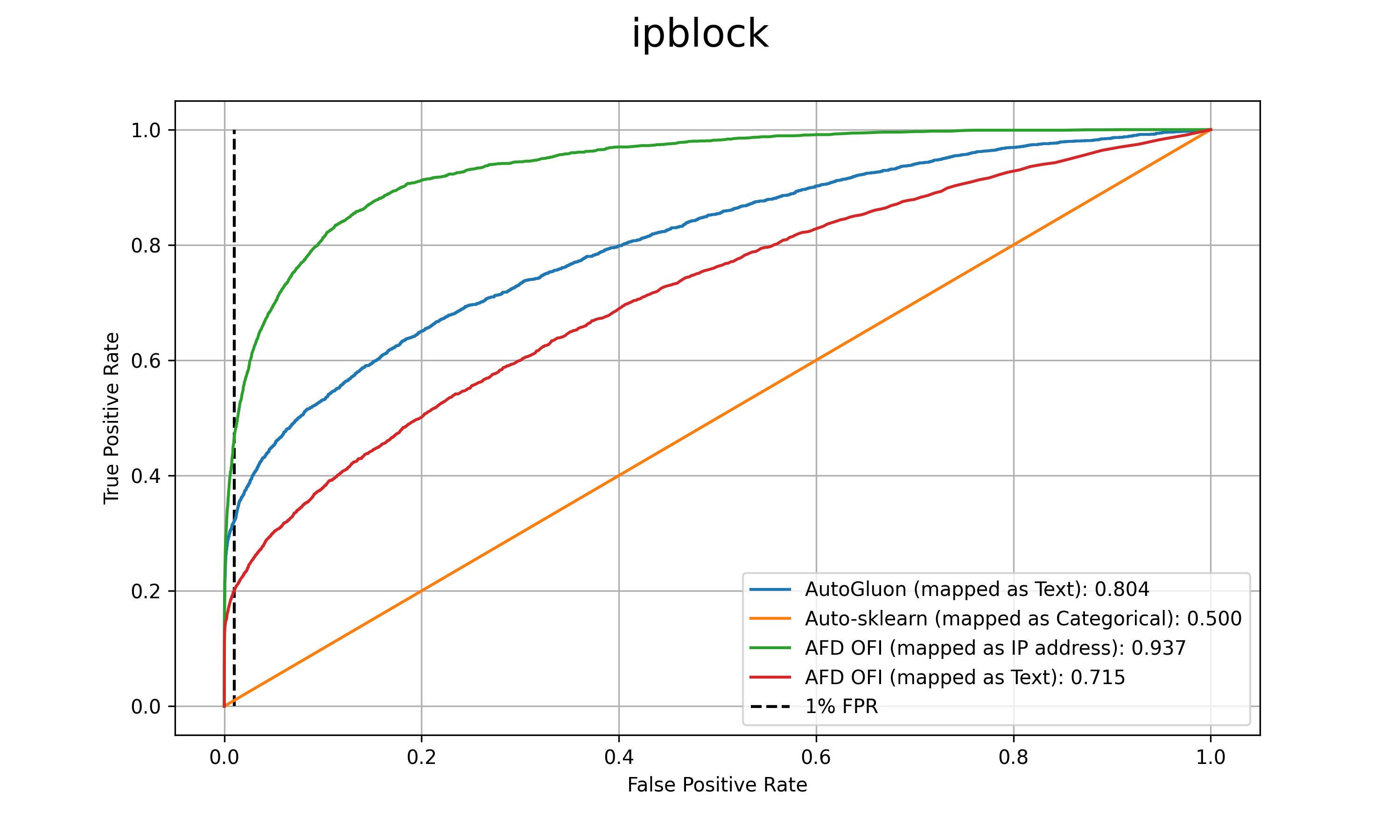
Standardized datasets and benchmarks have spurred innovations in computer vision, natural language processing, multi-modal and tabular settings. We note that, as compared to other well researched fields fraud detection has numerous differences. The differences include a high class imbalance, diverse feature types, frequently changing fraud patterns, and adversarial nature of the problem. Due to these differences, the modeling approaches that are designed for other classification tasks may not work well for the fraud detection. We introduce Fraud Dataset Benchmark (FDB), a compilation of publicly available datasets catered to fraud detection. FDB comprises variety of fraud related tasks, ranging from identifying fraudulent card-not-present transactions, detecting bot attacks, classifying malicious URLs, predicting risk of loan to content moderation. The Python based library from FDB provides consistent API for data loading with standardized training and testing splits. For reference, we also provide baseline evaluations of different modeling approaches on FDB. Considering the increasing popularity of Automated Machine Learning (AutoML) for various research and business problems, we used AutoML frameworks for our baseline evaluations. For fraud prevention, the organizations that operate with limited resources and lack ML expertise often hire a team of investigators, use blocklists and manual rules, all of which are inefficient and do not scale well. Such organizations can benefit from AutoML solutions that are easy to deploy in production and pass the bar of fraud prevention requirements. We hope that FDB helps in the development of customized fraud detection techniques catered to different fraud modus operandi (MOs) as well as in the improvement of AutoML systems that can work well for all datasets in the benchmark.
翻译:标准化的数据集和基准激发了计算机视野、自然语言处理、多式和表格设置方面的创新。我们注意到,与其他研究周密的领域相比,欺诈探测领域存在许多差异。这些差异包括高等级不平衡、不同特征类型、经常变化的欺诈模式和问题的对抗性质。由于这些差异,为其他分类任务设计的模型方法可能无法很好地探测欺诈。我们引入了欺诈数据集基准(FDB),汇编了公开提供的数据集,以侦测欺诈。FDB包含各种与欺诈有关的任务,从查明欺诈性卡不现交易、发现机器人袭击、对恶意的URL进行分类、预测贷款风险到内容温和度。基于FDB的Python图书馆提供一致的API装入标准化培训和测试分解的数据。我们还对FDB的不同模型方法进行基线评估。考虑到自动机器学习(Automilmal)对于各种研究和商业问题越来越受欢迎,我们使用自动ML框架来进行基线评估。对于防止欺诈的办法而言,使用不易变现的UR值的组织和ML系统常常使用低廉的流程,因为FML能够使ADL的系统受益。