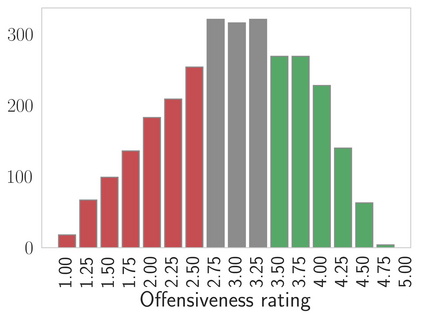
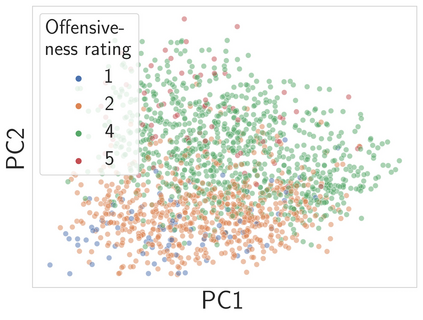
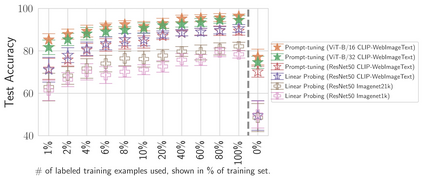
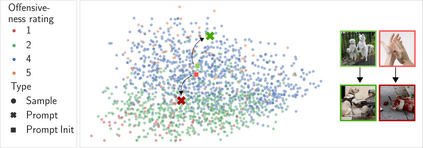
Probing or fine-tuning (large-scale) pre-trained models results in state-of-the-art performance for many NLP tasks and, more recently, even for computer vision tasks when combined with image data. Unfortunately, these approaches also entail severe risks. In particular, large image datasets automatically scraped from the web may contain derogatory terms as categories and offensive images, and may also underrepresent specific classes. Consequently, there is an urgent need to carefully document datasets and curate their content. Unfortunately, this process is tedious and error-prone. We show that pre-trained transformers themselves provide a methodology for the automated curation of large-scale vision datasets. Based on human-annotated examples and the implicit knowledge of a CLIP based model, we demonstrate that one can select relevant prompts for rating the offensiveness of an image. In addition to e.g. privacy violation and pornographic content previously identified in ImageNet, we demonstrate that our approach identifies further inappropriate and potentially offensive content.
翻译:测试或微调(大尺度)经过预先培训的模型导致许多NLP任务以及最近甚至计算机视觉任务与图像数据相结合时的先进性能。不幸的是,这些方法还带来严重的风险。特别是,从网络上自动剪掉的大型图像数据集可能包含贬义术语,作为类别和攻击性图像,也可能低于特定类别。因此,迫切需要仔细记录数据集并整理其内容。不幸的是,这一过程既烦琐又容易出错。我们表明,经过培训的变压器本身为大规模视觉数据集的自动整理提供了一种方法。根据人类附加说明的实例和基于 CLIP模型的隐含知识,我们证明,人们可以选择相关的时间来评定图像的冒犯性。例如,除了先前在图像网中发现的侵犯隐私和色情内容之外,我们证明我们的方法还查明了进一步不适当和潜在的冒犯性内容。