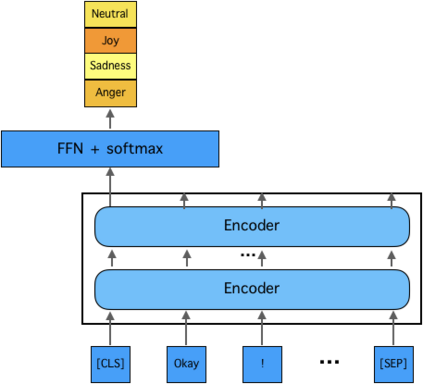
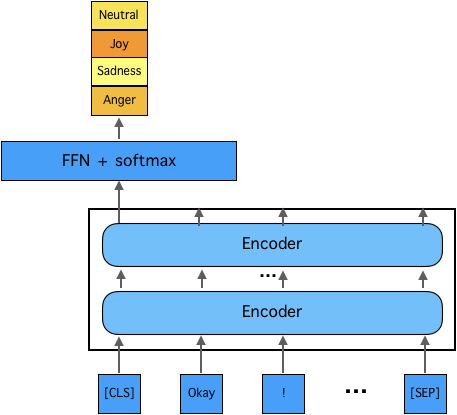
This paper describes our approach to the EmotionX-2019, the shared task of SocialNLP 2019. To detect emotion for each utterance of two datasets from the TV show Friends and Facebook chat log EmotionPush, we propose two-step deep learning based methodology: (i) encode each of the utterance into a sequence of vectors that represent its meaning; and (ii) use a simply softmax classifier to predict one of the emotions amongst four candidates that an utterance may carry. Notice that the source of labeled utterances is not rich, we utilise a well-trained model, known as BERT, to transfer part of the knowledge learned from a large amount of corpus to our model. We then focus on fine-tuning our model until it well fits to the in-domain data. The performance of the proposed model is evaluated by micro-F1 scores, i.e., 79.1% and 86.2% for the testsets of Friends and EmotionPush, respectively. Our model ranks 3rd among 11 submissions.
翻译:本文描述了我们对情感X-2019的处理方式,即2019年ScienceNLP的共同任务。为了检测电视节目Friends和Facebook聊天日志EmperiPush的两套数据集的每套话语的情绪,我们建议采取两步深层次的学习方法:(一) 将每套话词编码成代表其含义的矢量序列;(二) 使用简单的软麦分级器来预测四个候选人中可能含有的情绪之一。请注意,贴有标签的发音来源并不丰富,我们使用一个训练有素的模型,称为BERT,将从大量物质中学到的知识的一部分传授给我们的模型。我们然后侧重于微调我们的模型,直到它与主数据完全吻合;以及(二) 使用一个简单的软麦分码分类器,用来预测四个候选人中的情绪之一。注意,贴有标签的发音来源不丰富,我们使用一个称为BERT的模型,将我们从大量物质中学到的知识转移到我们的模型。我们然后侧重于微调我们的模型,直到它与主量数据完全吻合;拟议模型的性模型的性分别用微-F1分分数,即79.1%和86.2%和86.2%用于朋友和情感Push的试验。我们的第三位。