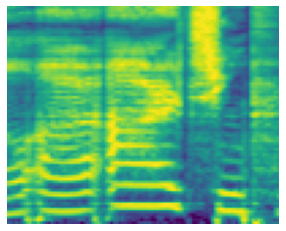
Singing voice conversion (SVC) is one promising technique which can enrich the way of human-computer interaction by endowing a computer the ability to produce high-fidelity and expressive singing voice. In this paper, we propose DiffSVC, an SVC system based on denoising diffusion probabilistic model. DiffSVC uses phonetic posteriorgrams (PPGs) as content features. A denoising module is trained in DiffSVC, which takes destroyed mel spectrogram produced by the diffusion/forward process and its corresponding step information as input to predict the added Gaussian noise. We use PPGs, fundamental frequency features and loudness features as auxiliary input to assist the denoising process. Experiments show that DiffSVC can achieve superior conversion performance in terms of naturalness and voice similarity to current state-of-the-art SVC approaches.
翻译:唱声转换( SVC) 是一种很有希望的技术,它能够通过赋予计算机以产生高菲度和表达式歌声的能力来丰富人类-计算机互动的方式。 在本文中,我们建议DiffSVC(基于分流扩散概率模型的SVC系统)作为基于分流扩散概率模型的SVC(SiffSVC)系统,DiffSVC(PPGs)使用语音后方位转换(PPPGs)作为内容特性。DiffSVC(DiffSVC)培训了一种分流模块,该模块将扩散/前方过程及其相应的步骤信息产生的被摧毁的光谱作为预测增加的高斯噪音的投入。我们使用PPGs(PPGs)、基本频率特征和声响度功能作为辅助投入,以协助分流过程。实验显示DiffSVC(PPC)在自然性和声音方面可以实现优异性转换性表现,并类似于当前最先进的SVC(SVC)方法。