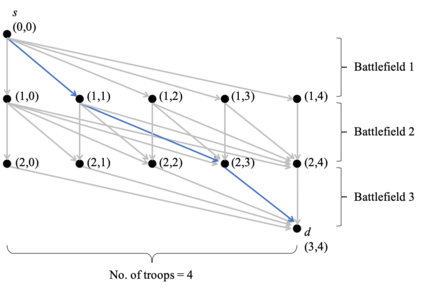
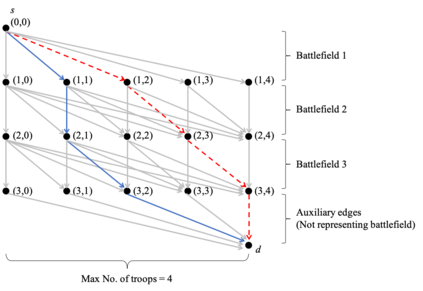
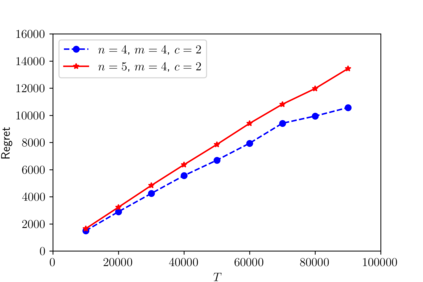
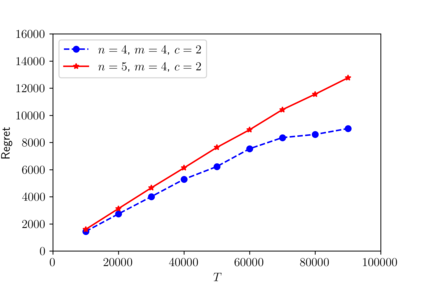
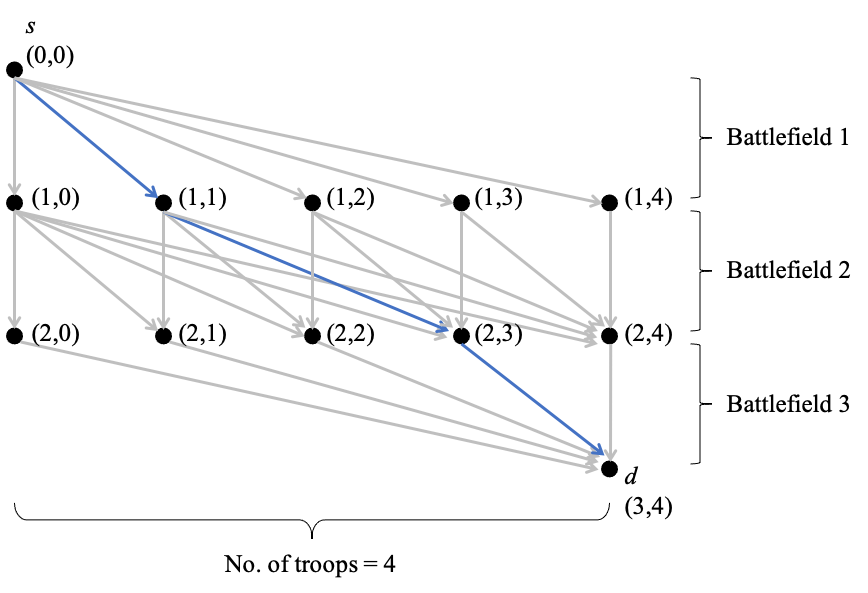
We consider a dynamic Colonel Blotto game (CBG) in which one of the players is the learner and has limited troops (budget) to allocate over a finite time horizon. At each stage, the learner strategically determines the budget distribution among the battlefields based on past observations. The other player is the adversary, who chooses its budget allocation strategies randomly from some fixed unknown distribution. The learner's objective is to minimize its regret, which is the difference between the payoff of the best mixed strategy and the realized payoff by following a learning algorithm. The dynamic CBG is analyzed under the framework of combinatorial bandit and bandit with knapsacks. We first convert the dynamic CBG with budget constraint to a path planning problem on a graph. We then devise an efficient dynamic policy for the learner that uses a combinatorial bandit algorithm Edge on the path planning graph as a subroutine for another algorithm LagrangeBwK. It is shown that under the proposed policy, the learner's regret is bounded with high probability by a term sublinear in time horizon $T$ and polynomial with respect to other parameters.
翻译:我们考虑的是具有活力的上校布洛托游戏(CBG),其中一名球员是学习者,而其部队(预算)在有限的时间范围内分配。在每个阶段,学习者根据以往的观察,从战略角度决定战场之间的预算分配。另一个球员是对手,从固定的未知分布中随机选择其预算分配战略。学习者的目标是尽量减少其遗憾,即最佳混合战略的得偿与根据学习算法实现的得偿之间的差别。动态CBG是在组合式强盗和带Knapsacks的强盗的框架内分析的。我们首先将带有预算限制的动态CBG转换为图表上的道路规划问题。我们随后为在路径规划图上使用组合式强盗算法作为另一个算法LagrangeBwK的子路程的学习者设计了一个有效的动态政策。根据拟议的政策,学习者的遗憾与高概率结合了在时空段的子线($T$美元和多盘图)与其他参数的参数。