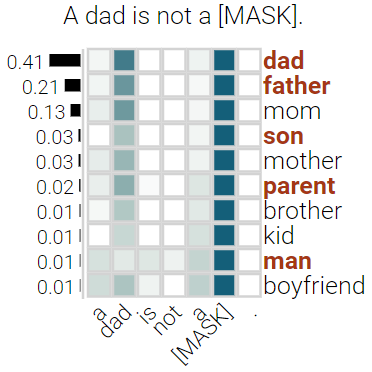
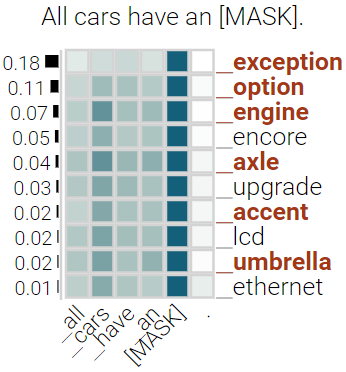
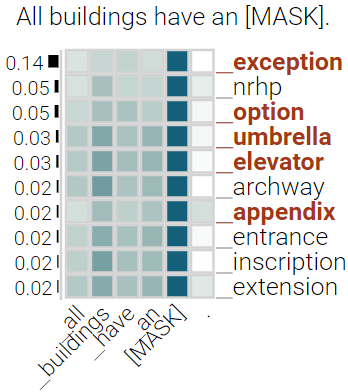
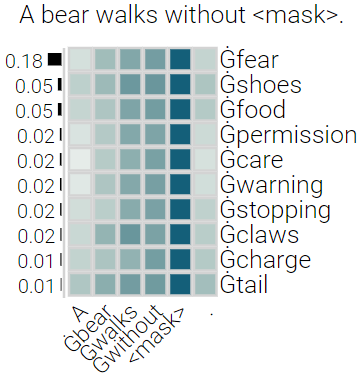
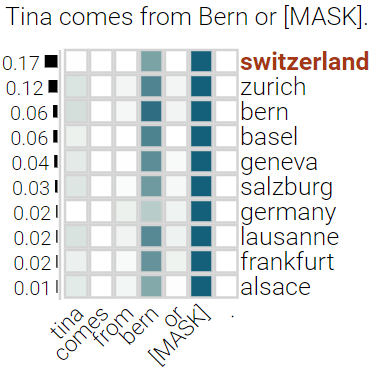
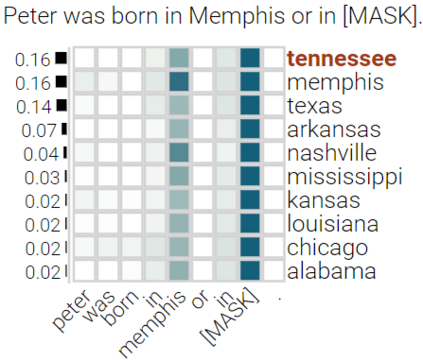
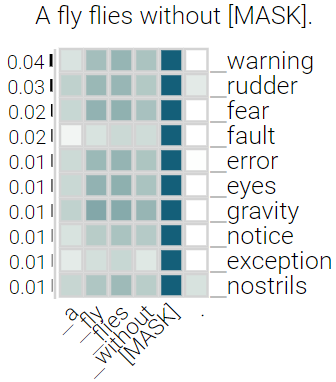
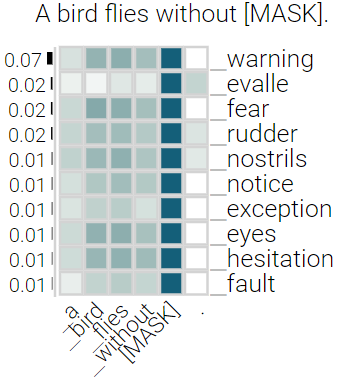
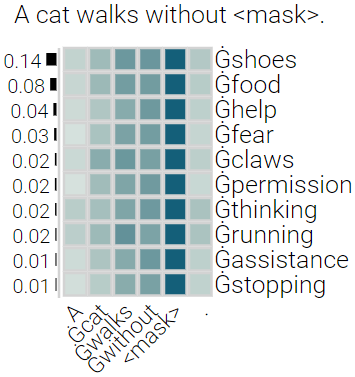
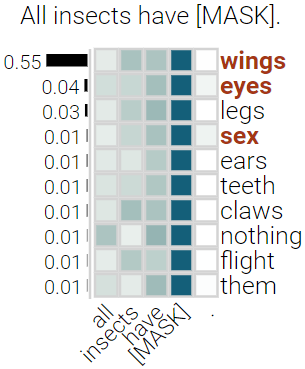
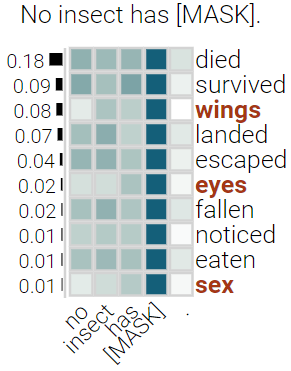
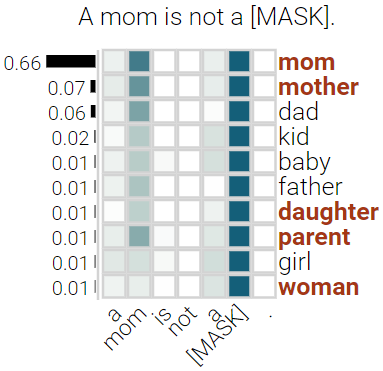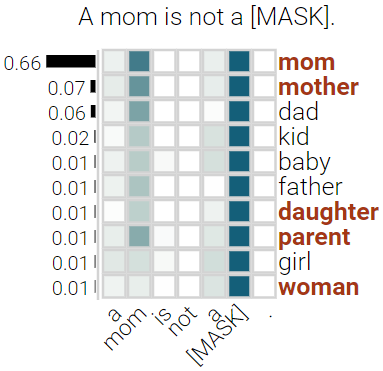With the success of contextualized language models, much research explores what these models really learn and in which cases they still fail. Most of this work focuses on specific NLP tasks and on the learning outcome. Little research has attempted to decouple the models' weaknesses from specific tasks and focus on the embeddings per se and their mode of learning. In this paper, we take up this research opportunity: based on theoretical linguistic insights, we explore whether the semantic constraints of function words are learned and how the surrounding context impacts their embeddings. We create suitable datasets, provide new insights into the inner workings of LMs vis-a-vis function words and implement an assisting visual web interface for qualitative analysis.
翻译:随着背景化语言模型的成功,许多研究探索了这些模型真正学到了什么,在哪些情况下它们仍然失败。这些研究大多侧重于具体的国家学习计划任务和学习成果。几乎没有研究试图将这些模型的弱点与具体任务区分开来,侧重于嵌入本身及其学习模式。在本论文中,我们抓住了这一研究机会:根据理论语言洞察力,我们探讨是否学习了功能词的语义限制,以及周围环境如何影响其嵌入。我们创建了合适的数据集,提供了对LMS相对于功能词的内部工作的新洞察力,并为定性分析建立了一个辅助的视觉网络界面。