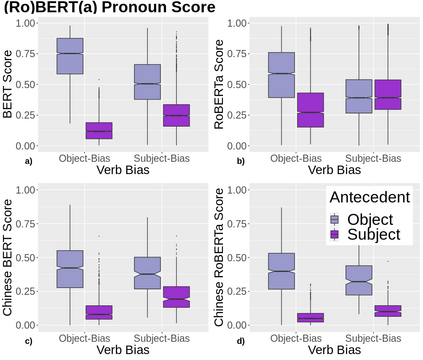
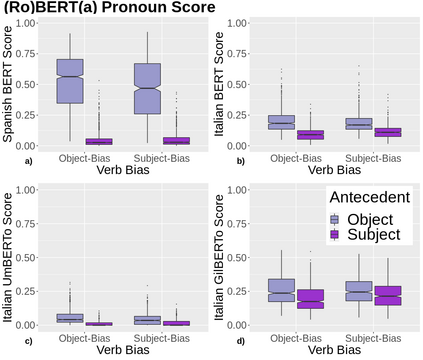
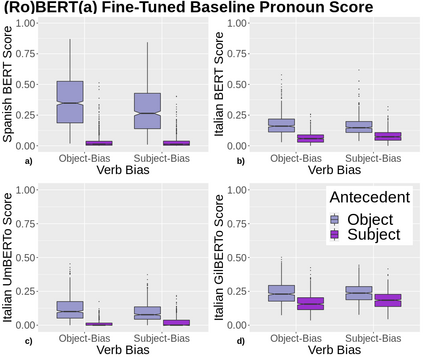
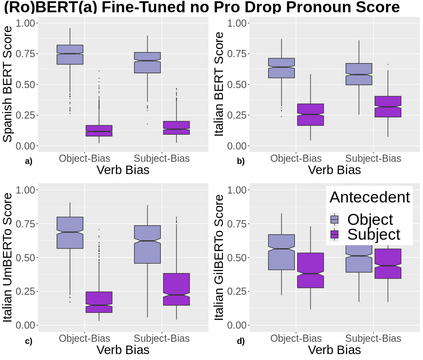
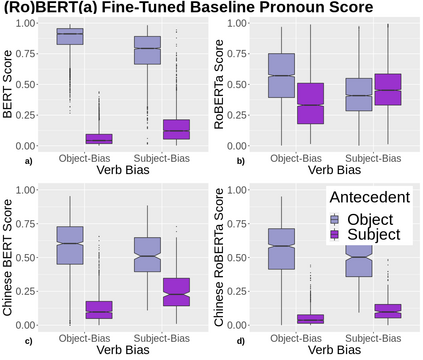
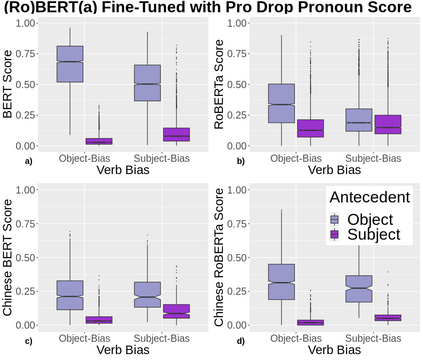
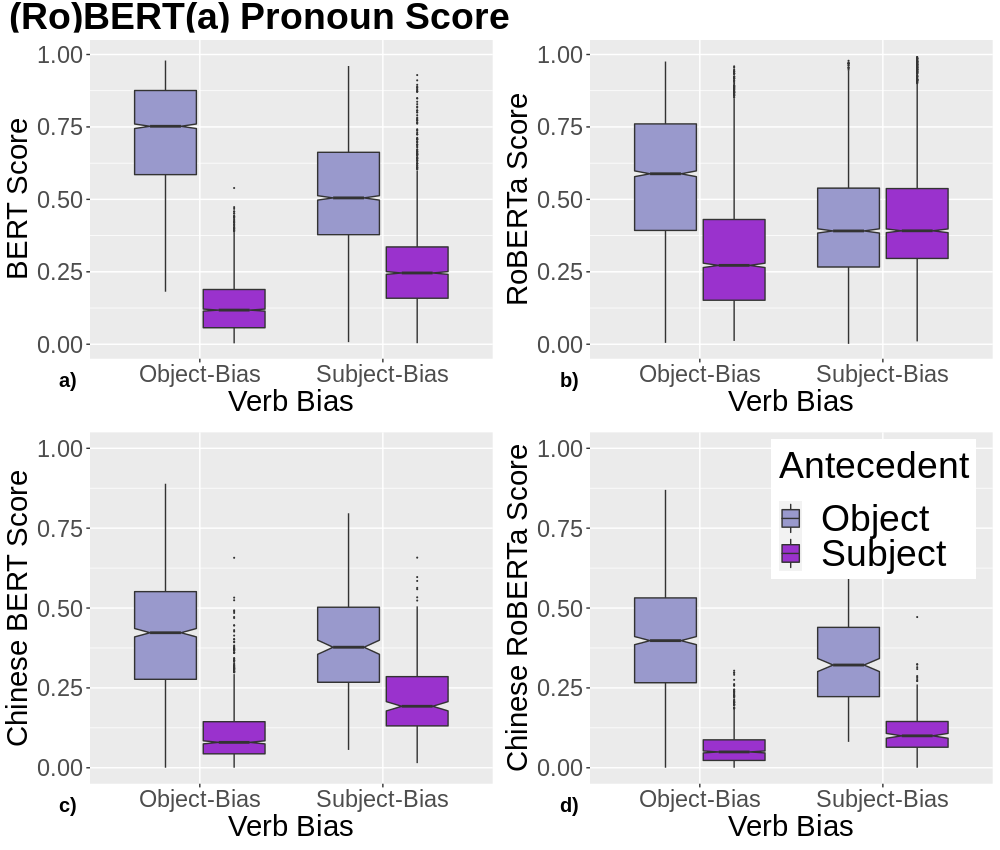
A growing body of literature has focused on detailing the linguistic knowledge embedded in large, pretrained language models. Existing work has shown that non-linguistic biases in models can drive model behavior away from linguistic generalizations. We hypothesized that competing linguistic processes within a language, rather than just non-linguistic model biases, could obscure underlying linguistic knowledge. We tested this claim by exploring a single phenomenon in four languages: English, Chinese, Spanish, and Italian. While human behavior has been found to be similar across languages, we find cross-linguistic variation in model behavior. We show that competing processes in a language act as constraints on model behavior and demonstrate that targeted fine-tuning can re-weight the learned constraints, uncovering otherwise dormant linguistic knowledge in models. Our results suggest that models need to learn both the linguistic constraints in a language and their relative ranking, with mismatches in either producing non-human-like behavior.
翻译:越来越多的文献侧重于详细介绍在大型、经过预先培训的语言模型中嵌入的语言知识。现有工作表明,模型中的非语言偏见可以驱使模式行为脱离语言一般化。我们假设,一种语言内部的竞争性语言过程,而不仅仅是非语言模式偏见,可能掩盖语言知识的基础。我们通过用四种语言(英语、中文、西班牙语和意大利语)探索单一现象来测试这一主张。虽然发现不同语言的人类行为相似,但我们发现模式行为中存在交叉语言差异。我们表明,一种语言的相互竞争过程会制约模式行为,并表明有针对性的微调可以重新权衡学到的制约因素,揭示模型中其他不活跃的语言知识。我们的结果表明,模式需要学习一种语言的语言限制及其相对等级,在产生非人性行为时两者之间互不匹配。