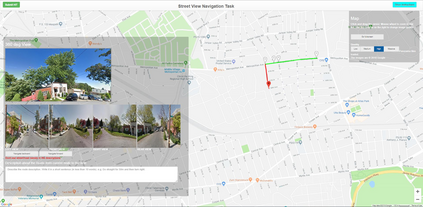
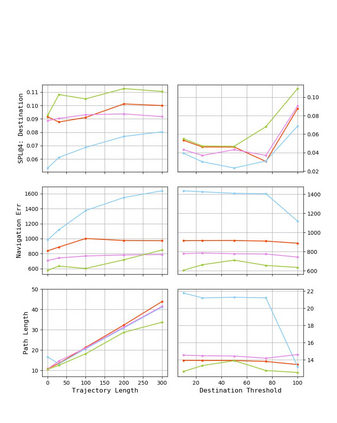
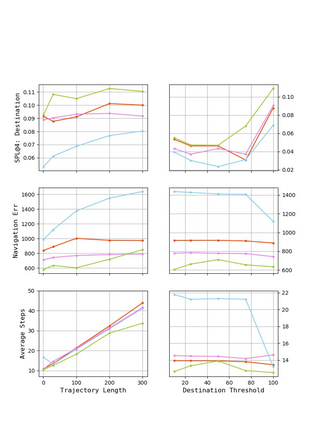
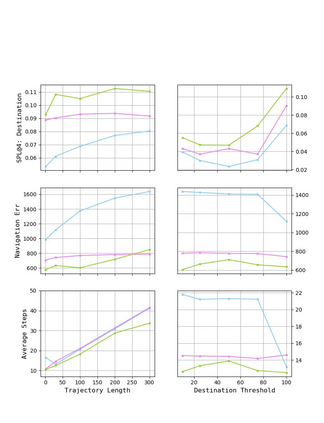
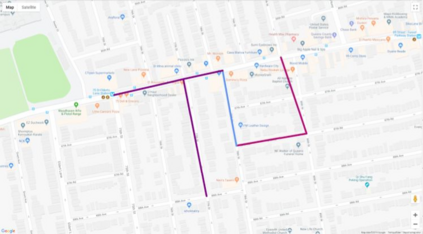
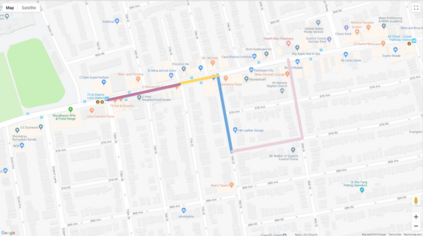
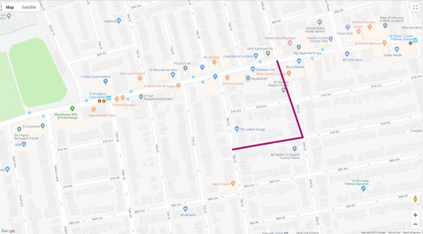
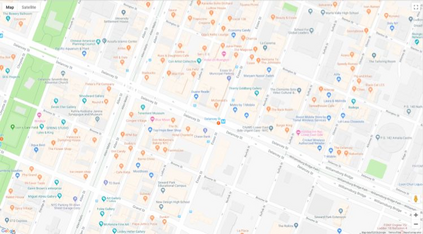
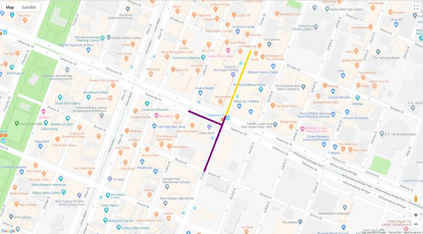
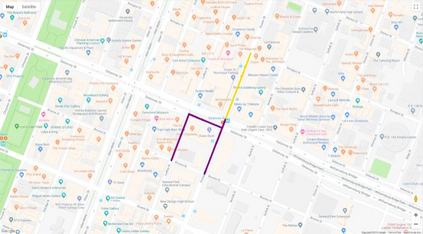
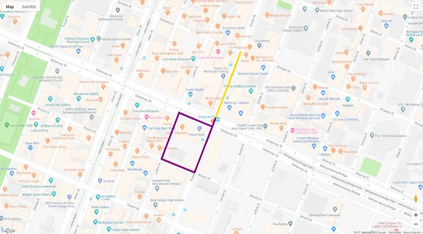
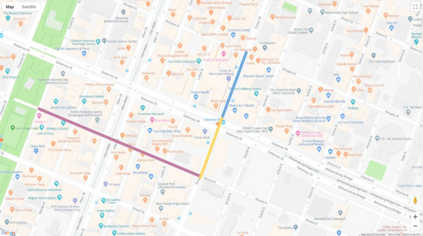
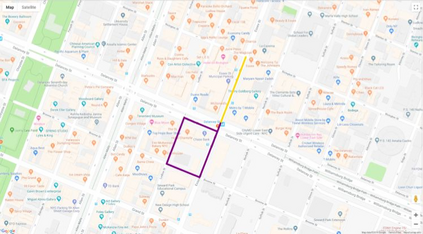
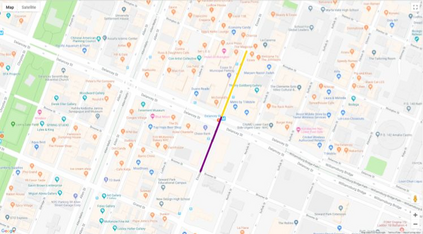
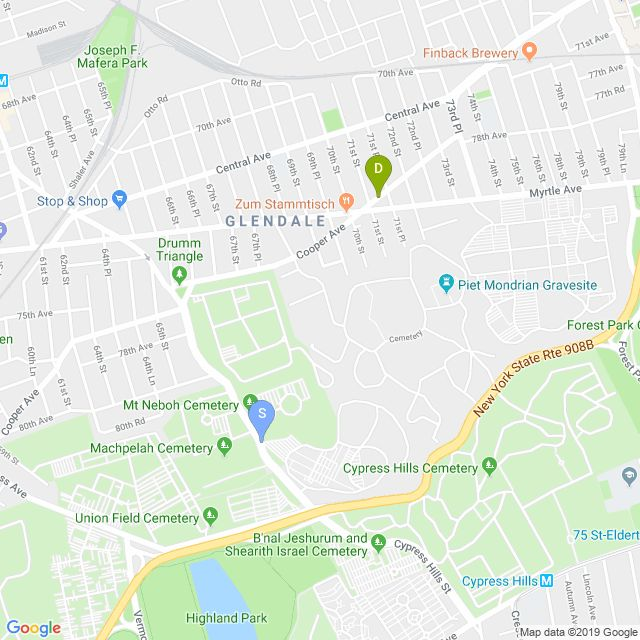
Autonomous driving models often consider the goal as fixed at the start of the ride. Yet, in practice, passengers will still want to influence the route, e.g. to pick up something along the way. In order to keep such inputs intuitive, we provide automatic way finding in cities based on verbal navigational instructions and street-view images. Our first contribution is the creation of a large-scale dataset with verbal navigation instructions. To this end, we have developed an interactive visual navigation environment based on Google Street View; we further design an annotation method to highlight mined anchor landmarks and local directions between them in order to help annotators formulate typical, human references to those. The annotation task was crowdsourced on the AMT platform, to construct a new Talk2Nav dataset with 10,714 routes. Our second contribution is a new learning method. Inspired by spatial cognition research on the mental conceptualization of navigational instructions, we introduce a soft attention mechanism defined over the segmented language instructions to jointly extract two partial instructions -- one for matching the next upcoming visual landmark and the other for matching the local directions to the next landmark. On the similar lines, we also introduce memory scheme to encode the local directional transitions. Our work takes advantage of the advance in two lines of research: mental formalization of verbal navigational instructions and training neural network agents for automatic way finding. Extensive experiments show that our method significantly outperforms previous navigation methods. For demo video, dataset and code, please refer to our \href{https://www.trace.ethz.ch/publications/2019/talk2nav/index.html}{project page}.
翻译:自动驾驶模型通常将目标视为在旅程开始时就固定的目标。 然而,在实践中,乘客仍想影响路线, 例如在路上收集某些信息。 为了保持这种投入的直观性, 我们提供在城市里自动找到基于口头导航指令和街道视图图像的路径。 我们的第一个贡献是创建带有口头导航指令的大型数据集。 为此, 我们开发了一个基于 Google Street View 的交互式视觉导航环境; 我们进一步设计了一个描述方法, 突出他们之间被埋设的锚标和本地方向, 以便帮助说明者制定典型的人类引用。 为了保持这种输入的直观性, 我们提供在 AMT 平台上聚集了群集, 以10, 714 条路径构建新的 Talk2Nav 数据集。 我们的第二个贡献是一个新的学习方法。 在对导航指令的心理概念化进行空间认知研究的启发下, 我们为分层语言指令引入一个软关注机制, 以联合提取两个部分指令 -- 用于匹配下一个视觉标志, 和另一个匹配本地方向的内脏指令 。 将显示我们自己的直线路路路路路路路的路径 。