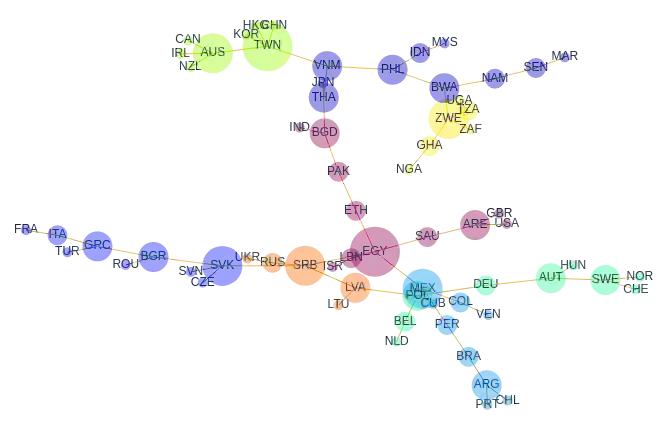
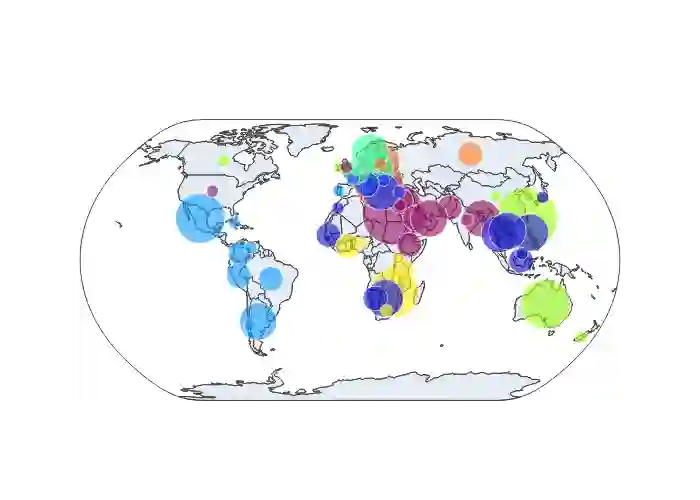
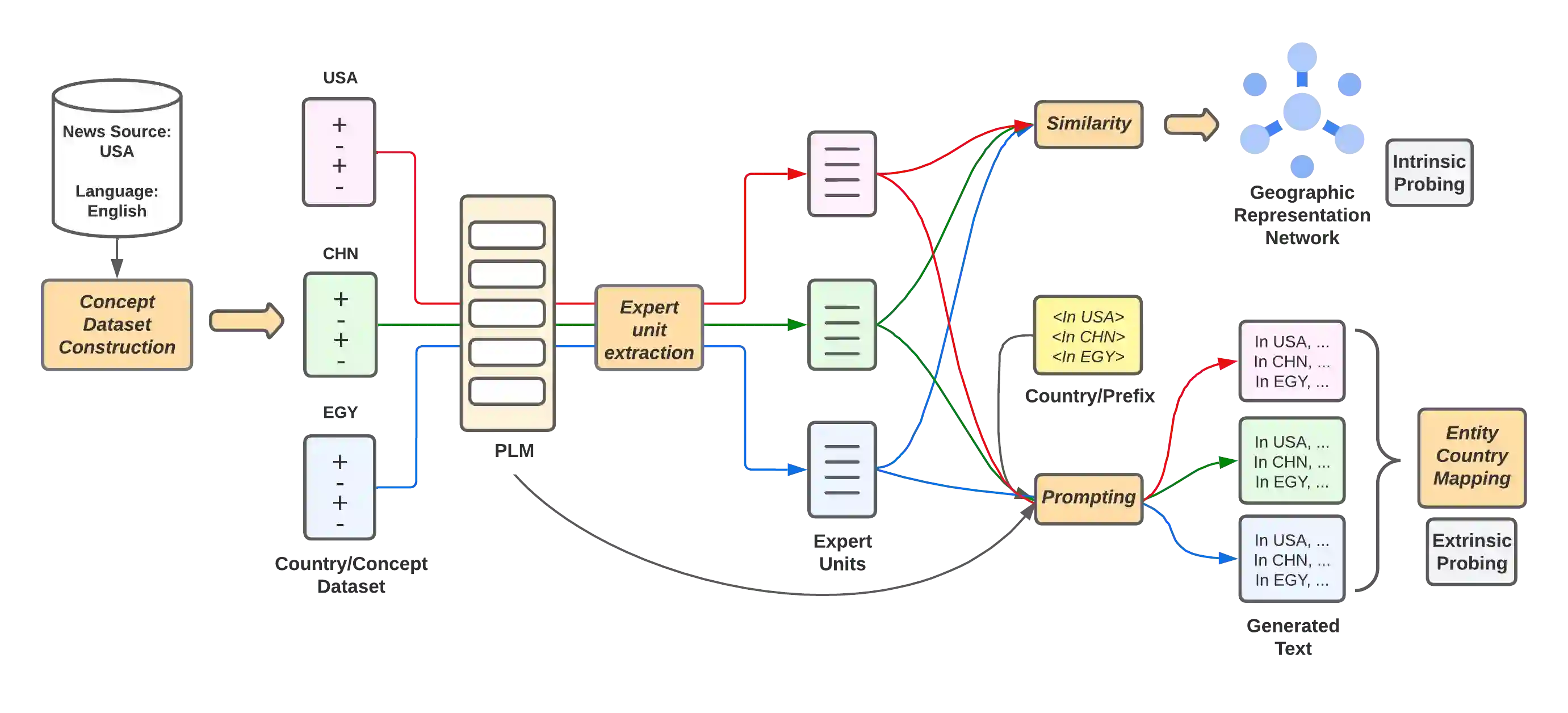
Pretrained language models (PLMs) often fail to fairly represent target users from certain world regions because of the under-representation of those regions in training datasets. With recent PLMs trained on enormous data sources, quantifying their potential biases is difficult, due to their black-box nature and the sheer scale of the data sources. In this work, we devise an approach to study the geographic bias (and knowledge) present in PLMs, proposing a Geographic-Representation Probing Framework adopting a self-conditioning method coupled with entity-country mappings. Our findings suggest PLMs' representations map surprisingly well to the physical world in terms of country-to-country associations, but this knowledge is unequally shared across languages. Last, we explain how large PLMs despite exhibiting notions of geographical proximity, over-amplify geopolitical favouritism at inference time.
翻译:受过训练的语言模型(PLM)往往不能公平代表某些世界区域的目标用户,因为这些区域在培训数据集中的代表性不足。由于最近对PLM进行了关于巨大数据源的培训,因此很难量化其潜在偏差,因为其黑盒性质和数据源的广度很大。在这项工作中,我们设计了一种方法来研究PLM中存在的地理偏差(和知识),提出一个地理代表演示框架,采用一种与实体国家绘图相结合的自我调节方法。我们的研究结果表明,PLM的表述在国与国之间联系方面对实体世界来说是令人惊讶的,但这种知识在各语文之间是不平等分享的。最后,我们解释了尽管存在地理相近的概念,但在推论时间却过度认可地缘政治偏好。