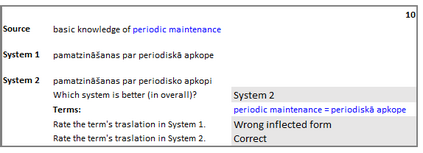
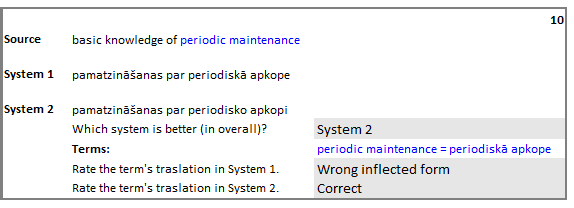
Most of the recent work on terminology integration in machine translation has assumed that terminology translations are given already inflected in forms that are suitable for the target language sentence. In day-to-day work of professional translators, however, it is seldom the case as translators work with bilingual glossaries where terms are given in their dictionary forms; finding the right target language form is part of the translation process. We argue that the requirement for apriori specified target language forms is unrealistic and impedes the practical applicability of previous work. In this work, we propose to train machine translation systems using a source-side data augmentation method that annotates randomly selected source language words with their target language lemmas. We show that systems trained on such augmented data are readily usable for terminology integration in real-life translation scenarios. Our experiments on terminology translation into the morphologically complex Baltic and Uralic languages show an improvement of up to 7 BLEU points over baseline systems with no means for terminology integration and an average improvement of 4 BLEU points over the previous work. Results of the human evaluation indicate a 47.7% absolute improvement over the previous work in term translation accuracy when translating into Latvian.
翻译:在专业笔译员的日常工作中,很少出现这样的情况:翻译员在双语词汇中工作,其术语以词典形式提供;找到正确的目标语言形式是翻译过程的一部分;我们争辩说,对优先指定目标语言形式的要求是不现实的,妨碍了以往工作的实际适用性;在这项工作中,我们提议使用一种源端数据增强方法来培训机器翻译系统,该方法应说明随机选定的源语言及其目标语言。我们表明,在这种强化数据方面受过培训的系统很容易用于将术语纳入实际翻译的情景中。我们关于将术语翻译成形态复杂的波罗的海和乌拉尔语的实验表明,与没有术语整合手段的基线系统相比,已经改进了多达7个BLEU点,比以往工作平均改进了4个BLEU点。 人类评估结果表明,在翻译成拉脱维亚语时,比先前的术语准确性工作提高了47.7%。