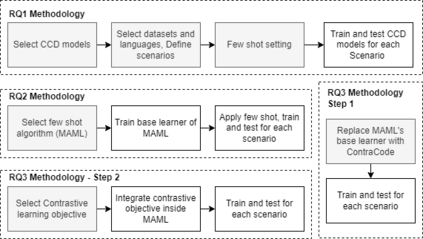
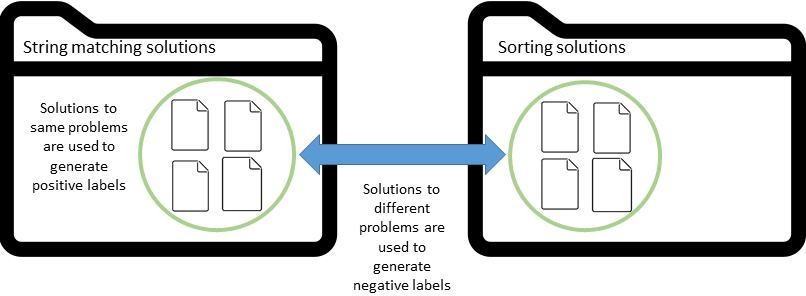
Context: Code Clone Detection (CCD) is a software engineering task that is used for plagiarism detection, code search, and code comprehension. Recently, deep learning-based models have achieved an F1 score (a metric used to assess classifiers) of $\sim$95\% on the CodeXGLUE benchmark. These models require many training data, mainly fine-tuned on Java or C++ datasets. However, no previous study evaluates the generalizability of these models where a limited amount of annotated data is available. Objective: The main objective of this research is to assess the ability of the CCD models as well as few shot learning algorithms for unseen programming problems and new languages (i.e., the model is not trained on these problems/languages). Method: We assess the generalizability of the state of the art models for CCD in few shot settings (i.e., only a few samples are available for fine-tuning) by setting three scenarios: i) unseen problems, ii) unseen languages, iii) combination of new languages and new problems. We choose three datasets of BigCloneBench, POJ-104, and CodeNet and Java, C++, and Ruby languages. Then, we employ Model Agnostic Meta-learning (MAML), where the model learns a meta-learner capable of extracting transferable knowledge from the train set; so that the model can be fine-tuned using a few samples. Finally, we combine contrastive learning with MAML to further study whether it can improve the results of MAML.
翻译:背景:代码克隆检测(CCD)是一项软件工程任务,用于进行斑象检测、代码搜索和代码理解。最近,深层次的学习模型在代码XGLUE基准基准上取得了F1分(用于评估分类的尺度)$sim$95 ⁇ 。这些模型需要许多培训数据,主要是在爪哇或C+++数据集上进行微调。然而,以往没有一项研究评估这些模型在可获得附加说明的数据数量有限的情况下的通用性。目标:本研究的主要目标是评估CCD模型的能力,以及很少为隐蔽的编程问题和新语言(即,该模型没有就这些问题/语言进行培训)。 方法:我们评估CCD在几处拍摄环境中的艺术模型的可概括性(即,只有少量的样本可以进行微调),方法是设定三种模式:(一) 看不见的问题,二) 看不见的语言,三) 新的语言和新的问题组合。我们选择了三种BICMET模型(即MMANet的精细数据集, MAMLA-MLMLA的学习结果,我们使用MLA-MLA的精选的模型学习。