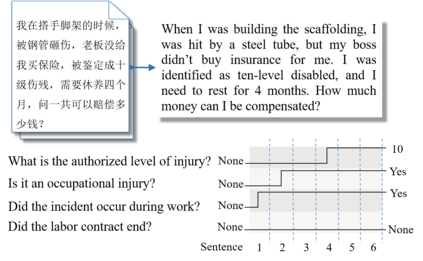
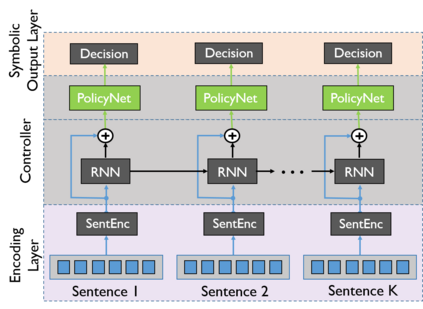
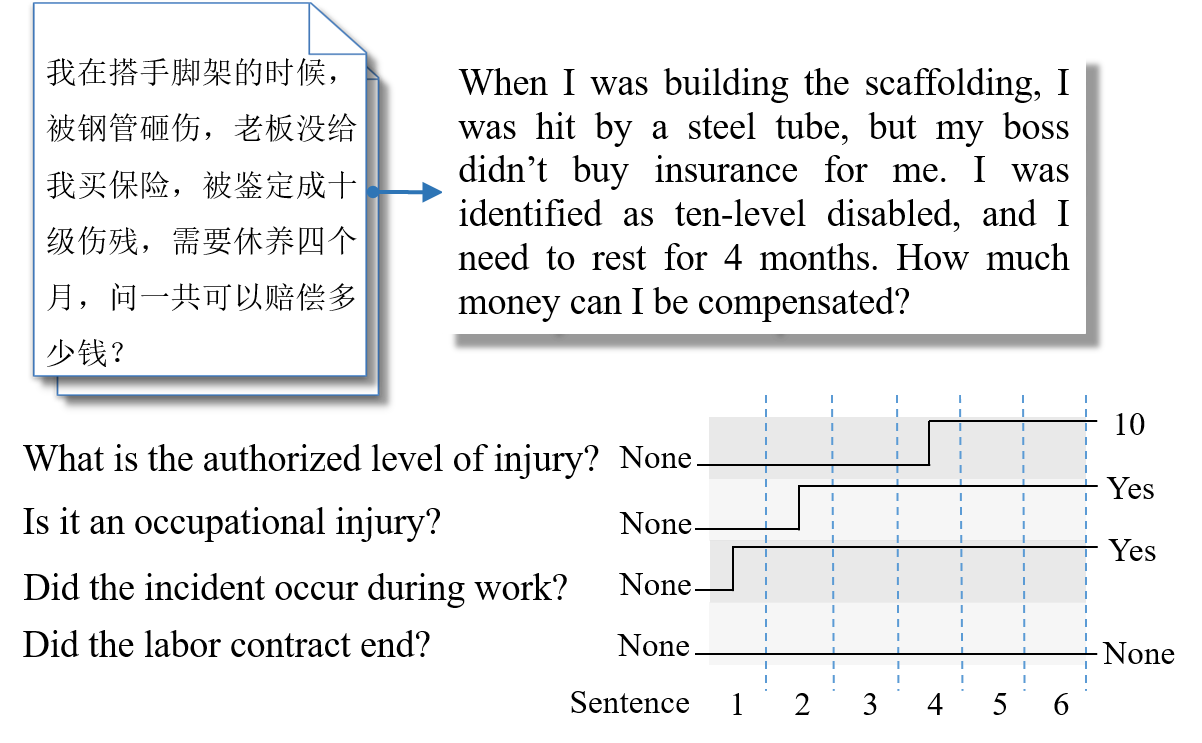
In early years, text classification is typically accomplished by feature-based machine learning models; recently, deep neural networks, as a powerful learning machine, make it possible to work with raw input as the text stands. However, exiting end-to-end neural networks lack explicit interpretation of the prediction. In this paper, we propose a novel framework, JUMPER, inspired by the cognitive process of text reading, that models text classification as a sequential decision process. Basically, JUMPER is a neural system that scans a piece of text sequentially and makes classification decisions at the time it wishes. Both the classification result and when to make the classification are part of the decision process, which is controlled by a policy network and trained with reinforcement learning. Experimental results show that a properly trained JUMPER has the following properties: (1) It can make decisions whenever the evidence is enough, therefore reducing total text reading by 30-40% and often finding the key rationale of prediction. (2) It achieves classification accuracy better than or comparable to state-of-the-art models in several benchmark and industrial datasets.
翻译:在早期,文本分类通常由基于地貌的机器学习模型完成;最近,深神经网络,作为一个强大的学习机器,使得有可能按现有文本使用原始输入进行工作;然而,退出的端到端神经网络缺乏对预测的明确解释。在本文中,我们提议了一个新框架,即JUMPER, 受文字阅读认知过程的启发,将示范文本分类作为一个顺序决定过程。基本上,JUMPER是一个神经系统,按顺序扫描一段文字,并在它希望的时候作出分类决定。分类结果和何时使分类成为决策过程的一部分,由政策网络控制,并经过强化学习培训。实验结果显示,经过适当培训的JUMPER具有以下属性:(1) 只要证据足够,就可以作出决定,从而将总读数减少30-40%,并常常找到关键的预测理由。(2) 分类准确性优于或可与几个基准和工业数据集中的最新模型相比。