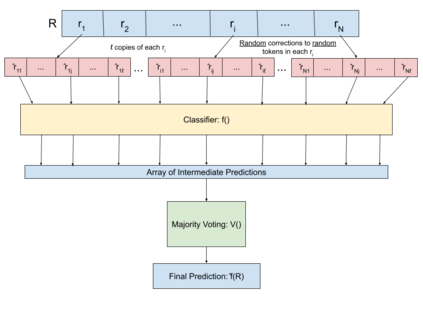
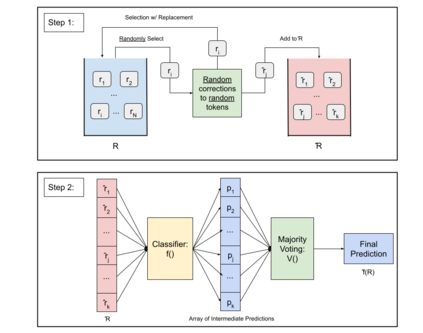
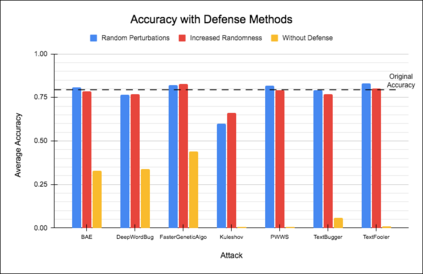
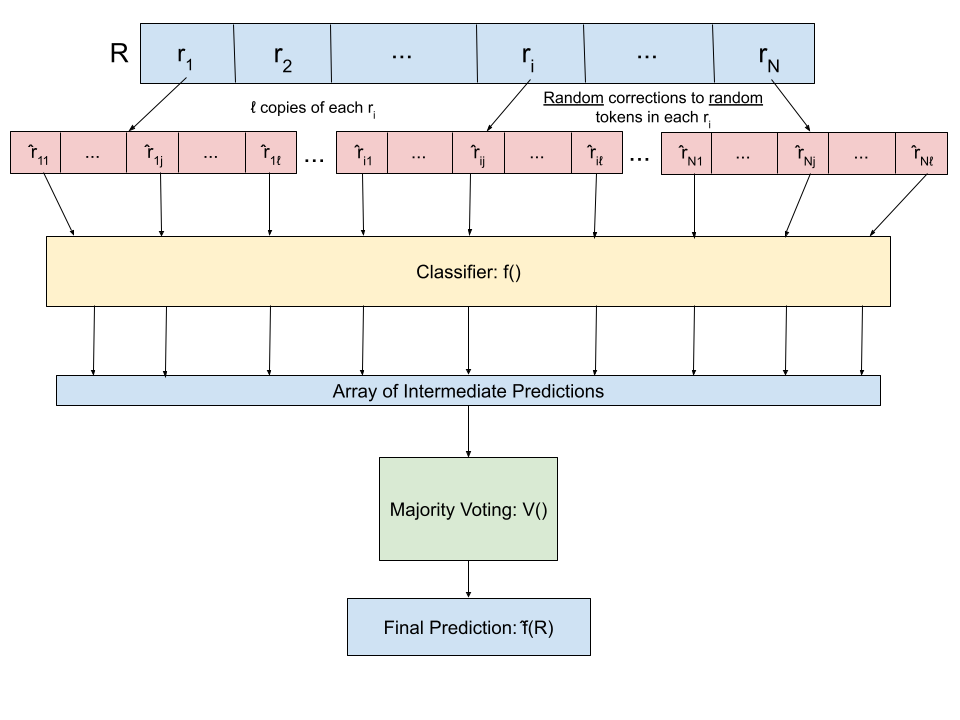
Attacks on deep learning models are often difficult to identify and therefore are difficult to protect against. This problem is exacerbated by the use of public datasets that typically are not manually inspected before use. In this paper, we offer a solution to this vulnerability by using, during testing, random perturbations such as spelling correction if necessary, substitution by random synonym, or simply dropping the word. These perturbations are applied to random words in random sentences to defend NLP models against adversarial attacks. Our Random Perturbations Defense and Increased Randomness Defense methods are successful in returning attacked models to similar accuracy of models before attacks. The original accuracy of the model used in this work is 80% for sentiment classification. After undergoing attacks, the accuracy drops to accuracy between 0% and 44%. After applying our defense methods, the accuracy of the model is returned to the original accuracy within statistical significance.
翻译:对深层学习模型的袭击往往难以识别,因此难以防范。 使用通常在使用前没有人工检查的公共数据集加剧了这一问题。 在本文中,我们通过在测试期间使用随机扰动,例如必要时使用拼写校正、用随机同义词取代或简单地丢弃字词,来解决这种脆弱性。 这些扰动适用于随机判决中的随机词,以保卫NLP模式免遭对抗性攻击。 我们的随机扰动防御和增加随机防御方法成功地将受攻击的模型退回到攻击前的类似模型的准确性。 本文中使用的模型的原始准确性在情绪分类方面为80%。 在进行攻击后,准确性在0%至44%之间下降。 在应用我们的防御方法后,模型的准确性在统计意义范围内返回到原始准确性。