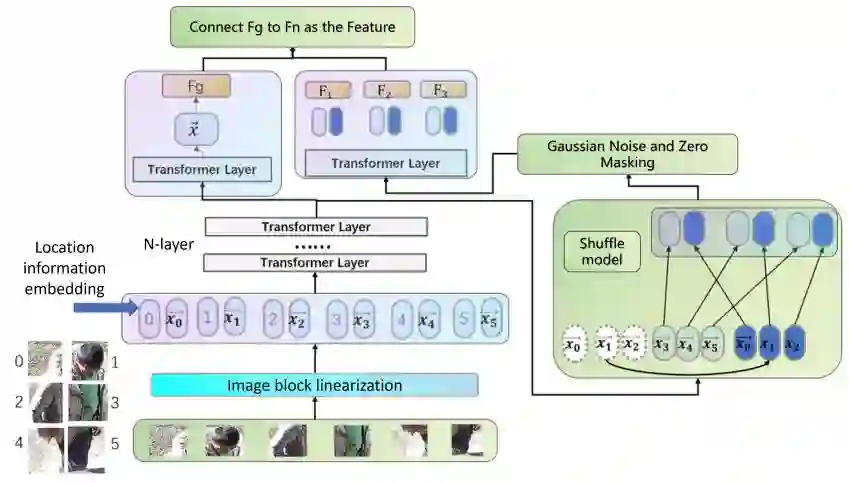
Person re-identification (ReID) in surveillance is challenged by occlusion, viewpoint distortion, and poor image quality. Most existing methods rely on complex modules or perform well only on clear frontal images. We propose Sh-ViT (Shuffling Vision Transformer), a lightweight and robust model for occluded person ReID. Built on ViT-Base, Sh-ViT introduces three components: First, a Shuffle module in the final Transformer layer to break spatial correlations and enhance robustness to occlusion and blur; Second, scenario-adapted augmentation (geometric transforms, erasing, blur, and color adjustment) to simulate surveillance conditions; Third, DeiT-based knowledge distillation to improve learning with limited labels.To support real-world evaluation, we construct the MyTT dataset, containing over 10,000 pedestrians and 30,000+ images from base station inspections, with frequent equipment occlusion and camera variations. Experiments show that Sh-ViT achieves 83.2% Rank-1 and 80.1% mAP on MyTT, outperforming CNN and ViT baselines, and 94.6% Rank-1 and 87.5% mAP on Market1501, surpassing state-of-the-art methods.In summary, Sh-ViT improves robustness to occlusion and blur without external modules, offering a practical solution for surveillance-based personnel monitoring.
翻译:监控场景中的行人重识别(ReID)面临着遮挡、视角畸变和图像质量不佳等挑战。现有方法大多依赖复杂模块,或仅在清晰正面图像上表现良好。本文提出Sh-ViT(Shuffling Vision Transformer),一种用于遮挡行人重识别的轻量且鲁棒的模型。该模型基于ViT-Base架构,引入三个核心组件:首先,在最终Transformer层中设计Shuffle模块,以打破空间相关性并增强对遮挡与模糊的鲁棒性;其次,采用场景自适应数据增强(包括几何变换、擦除、模糊和色彩调整)来模拟实际监控条件;第三,基于DeiT的知识蒸馏策略,以在有限标注数据下提升学习效果。为支持真实场景评估,我们构建了MyTT数据集,包含基站巡检场景中超过10,000名行人和30,000余张图像,其中频繁出现设备遮挡和相机视角变化。实验表明,Sh-ViT在MyTT数据集上达到83.2%的Rank-1准确率和80.1%的mAP,优于CNN与ViT基线模型;在Market1501数据集上取得94.6%的Rank-1准确率和87.5%的mAP,超越了当前最先进方法。综上所述,Sh-ViT在不依赖外部模块的情况下提升了对遮挡与模糊的鲁棒性,为基于监控的人员监测提供了实用解决方案。