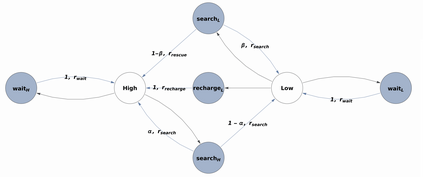
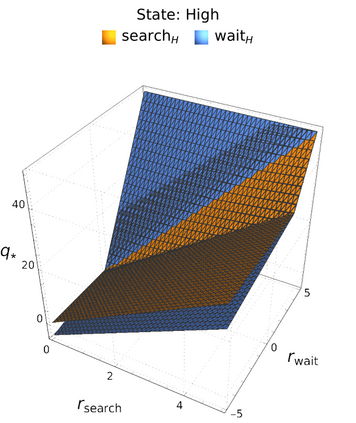
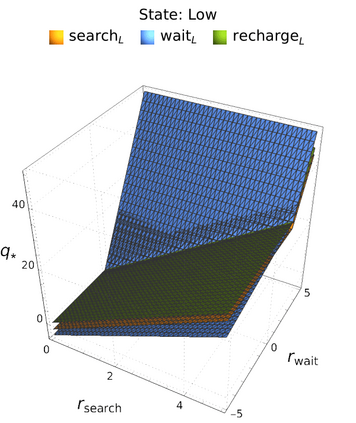
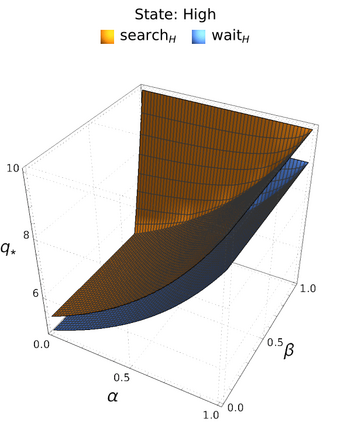
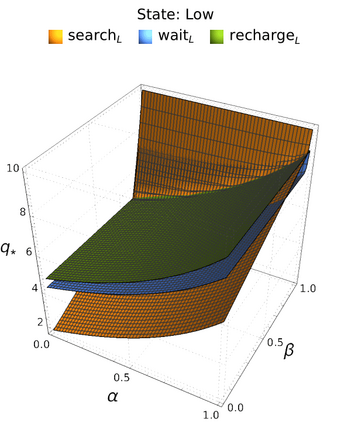
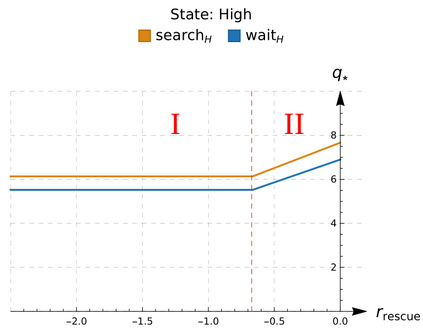
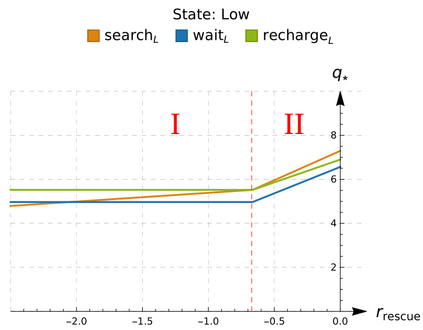
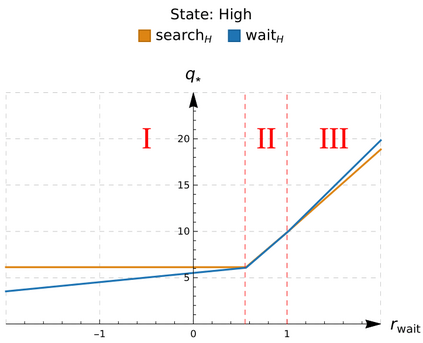
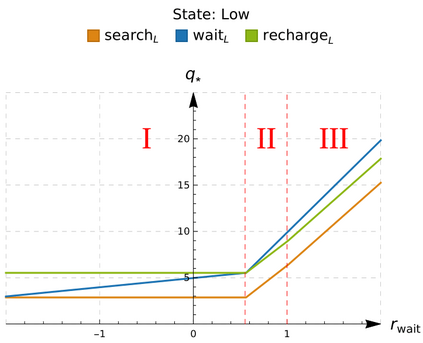
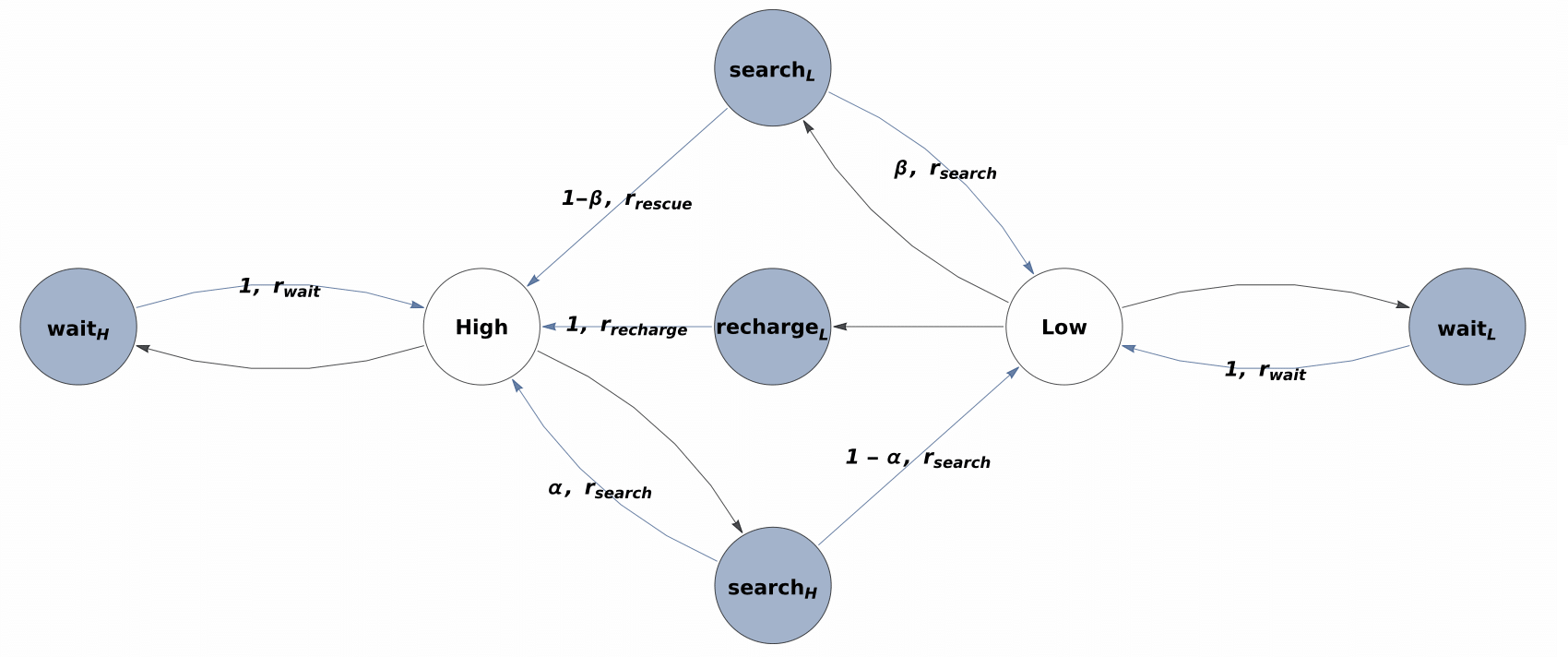
An in-depth understanding of the particular environment is crucial in reinforcement learning (RL). To address this challenge, the decision-making process of a mobile collaborative robotic assistant modeled by the Markov decision process (MDP) framework is studied in this paper. The optimal state-action combinations of the MDP are calculated with the non-linear Bellman optimality equations. This system of equations can be solved with relative ease by the computational power of Wolfram Mathematica, where the obtained optimal action-values point to the optimal policy. Unlike other RL algorithms, this methodology does not approximate the optimal behavior, it gives the exact, explicit solution, which provides a strong foundation for our study. With this, we offer new insights into understanding the action selection mechanisms in RL by presenting various small modifications on the very same schema that lead to different optimal policies.
翻译:深入了解特定环境对于强化学习至关重要。 为了应对这一挑战,本文件研究了以Markov决定程序(MDP)框架为模型的移动协作机器人助理的决策过程。MDP的最佳状态-行动组合是用非线性贝尔曼最佳公式计算出来的。这一方程式系统可以通过沃尔夫拉姆数学的计算能力相对轻松地解决,因为沃尔夫拉姆数学的计算能力是最佳行动价值指向最佳政策的。与其他RL算法不同,这种方法并不接近于最佳行为,它提供了准确、明确的解决方案,为我们的研究提供了坚实的基础。有了这个方法,我们提出了新的见解,通过对导致不同最佳政策的相同模式进行各种小的修改,来理解RL的行动选择机制。