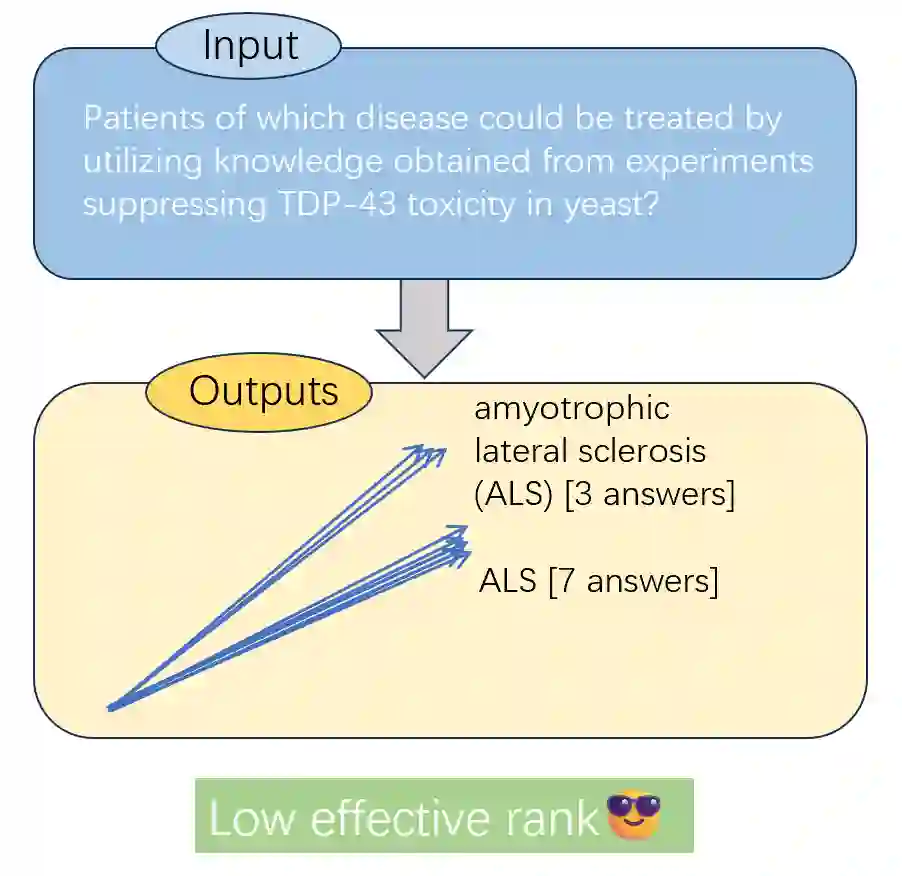
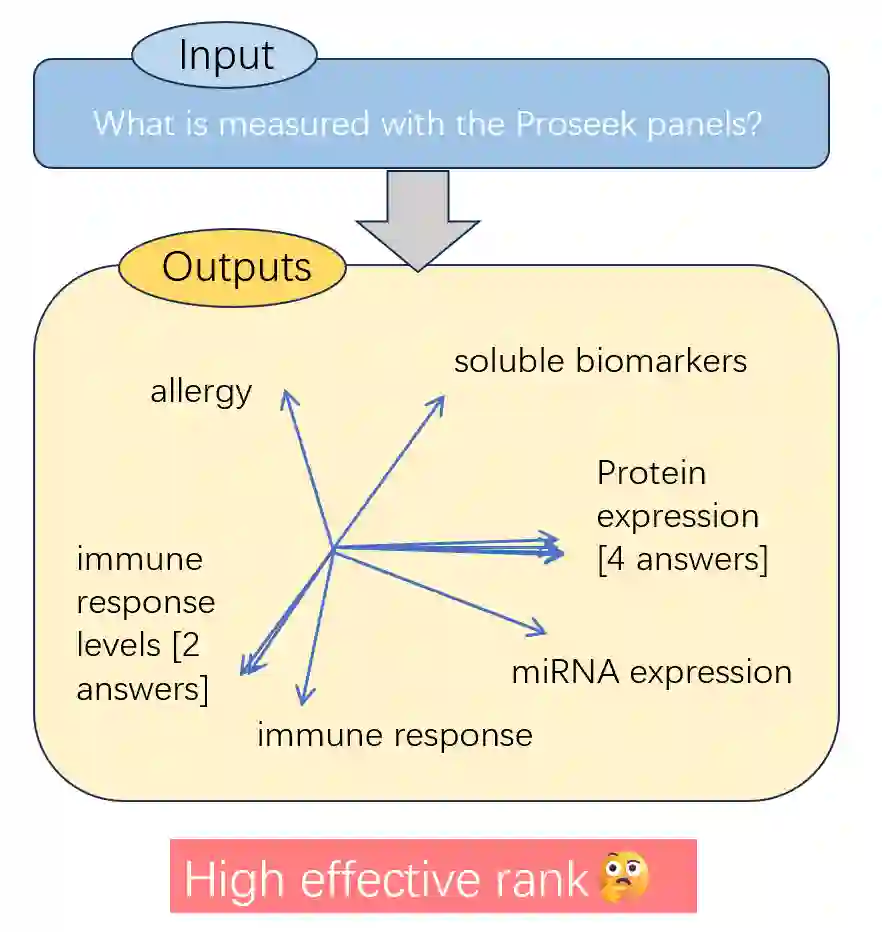
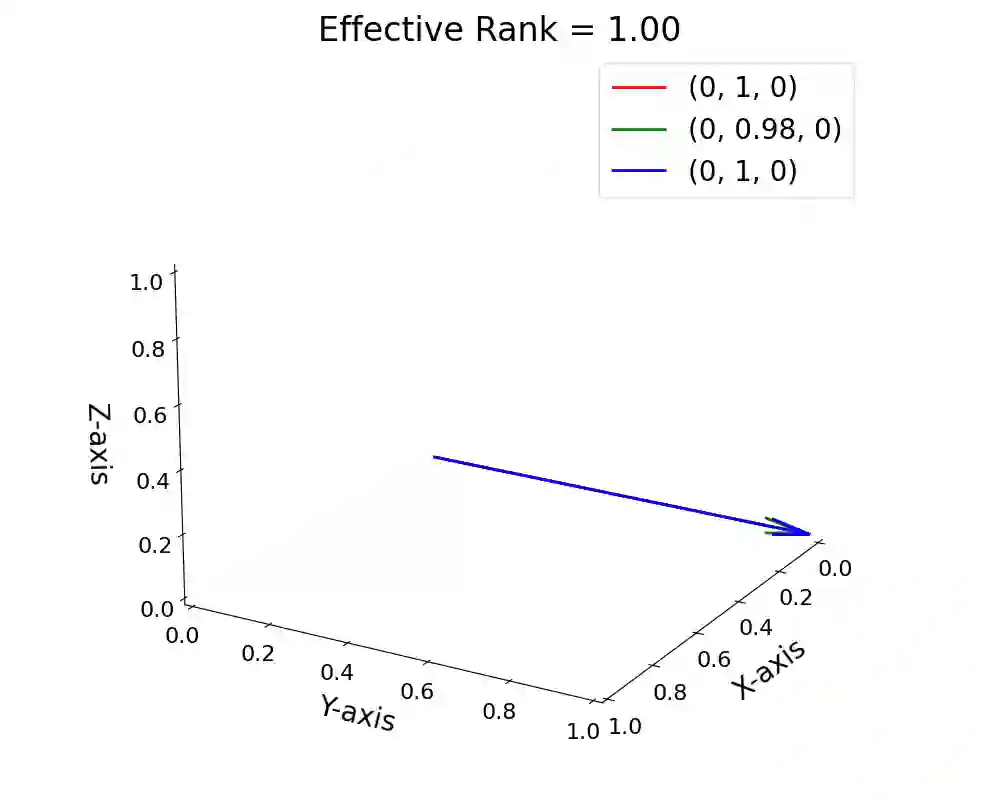
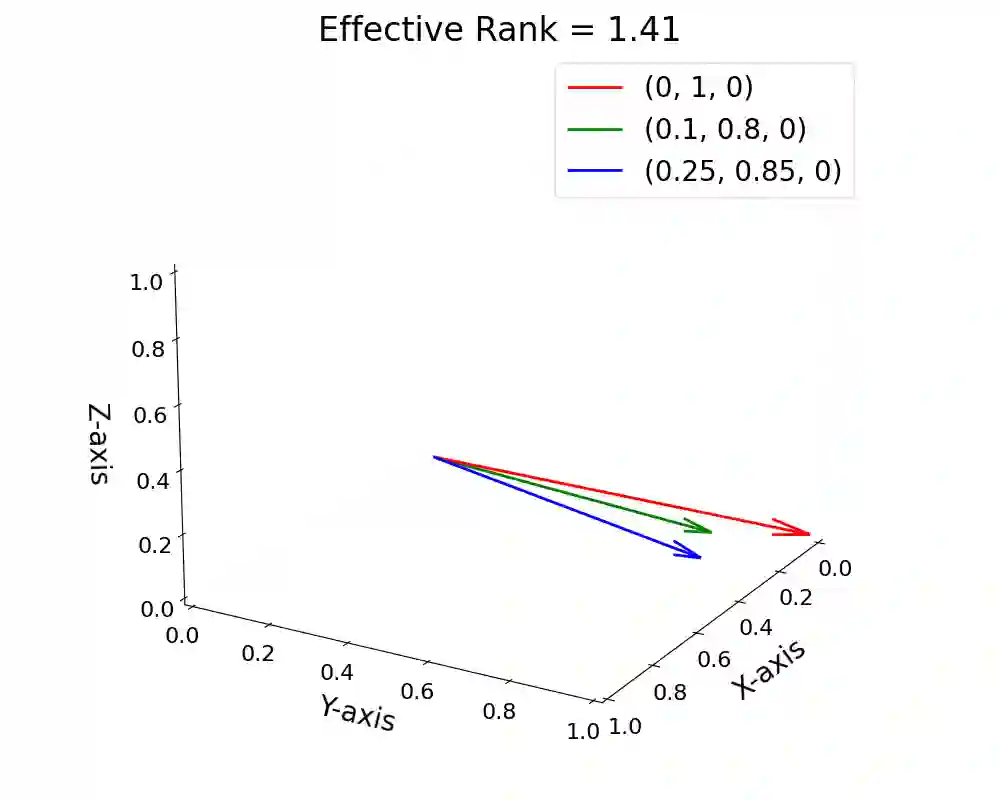
Detecting hallucinations in large language models (LLMs) remains a fundamental challenge for their trustworthy deployment. Going beyond basic uncertainty-driven hallucination detection frameworks, we propose a simple yet powerful method that quantifies uncertainty by measuring the effective rank of hidden states derived from multiple model outputs and different layers. Grounded in the spectral analysis of representations, our approach provides interpretable insights into the model's internal reasoning process through semantic variations, while requiring no extra knowledge or additional modules, thus offering a combination of theoretical elegance and practical efficiency. Meanwhile, we theoretically demonstrate the necessity of quantifying uncertainty both internally (representations of a single response) and externally (different responses), providing a justification for using representations among different layers and responses from LLMs to detect hallucinations. Extensive experiments demonstrate that our method effectively detects hallucinations and generalizes robustly across various scenarios, contributing to a new paradigm of hallucination detection for LLM truthfulness.
翻译:检测大型语言模型(LLMs)中的幻觉仍是实现其可信部署的核心挑战。本文超越基础的不确定性驱动幻觉检测框架,提出一种简洁而强大的方法:通过测量源自多个模型输出及不同层隐藏状态的有效秩来量化不确定性。基于表征的谱分析,该方法通过语义变化为模型内部推理过程提供可解释的洞察,且无需额外知识或附加模块,兼具理论优雅性与实践高效性。同时,我们从理论上论证了同时量化内部(单次响应的表征)与外部(不同响应)不确定性的必要性,为利用LLMs不同层的表征及多样响应检测幻觉提供了理论依据。大量实验表明,本方法能有效检测幻觉并在多种场景中保持稳健的泛化能力,为LLM真实性检测的幻觉检测范式提供了新思路。