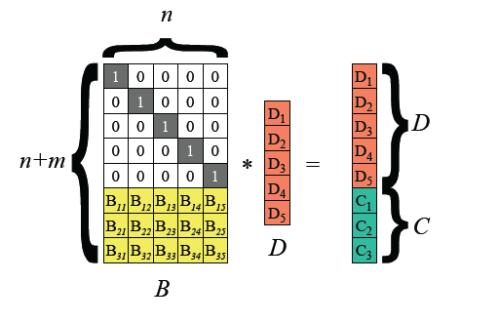
Deep-learning-based recommendation models (DLRMs) are widely deployed to serve personalized content to users. DLRMs are large in size due to their use of large embedding tables, and are trained by distributing the model across the memory of tens or hundreds of servers. Server failures are common in such large distributed systems and must be mitigated to enable training to progress. Checkpointing is the primary approach used for fault tolerance in these systems, but incurs significant training-time overhead both during normal operation and when recovering from failures. As these overheads increase with DLRM size, checkpointing is slated to become an even larger overhead for future DLRMs, which are expected to grow in size. This calls for rethinking fault tolerance in DLRM training. We present ECRM, a DLRM training system that achieves efficient fault tolerance using erasure coding. ECRM chooses which DLRM parameters to encode, correctly and efficiently updates parities, and enables training to proceed without any pauses, while maintaining consistency of the recovered parameters. We implement ECRM atop XDL, an open-source, industrial-scale DLRM training system. Compared to checkpointing, ECRM reduces training-time overhead for large DLRMs by up to 88%, recovers from failures up to 10.3$\times$ faster, and allows training to proceed during recovery. These results show the promise of erasure coding in imparting efficient fault tolerance to training current and future DLRMs.
翻译:深度学习建议模式(DLRM)被广泛用于为用户提供个性化内容。 DLRM由于使用大型嵌入表而规模很大,并且经过培训,在数十或数百个服务器的记忆中分发模型。服务器故障在大型分布式系统中很常见,必须减轻,以便培训取得进展。检查是这些系统中用于防错度的主要方法,但在正常运行期间和从故障中都产生大量的培训时间管理费。随着这些间接费用随着DLRM规模的扩大而增加,检查将变成未来DLRMM的更大管理费。这要求在DLRM培训中重新思考差错容忍度。我们介绍ECRM,一个DLRM培训系统,通过取消编码、正确和高效更新平衡度,使这些培训在不中断的情况下进行,同时保持回收参数的一致性。我们实施ECRMMRM、开放源码、工业级培训到大规模DRMRMA的回收期,使EC的DRMM升级到D的恢复期,使EC-RMRRM的恢复过程比重。