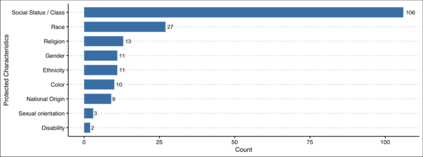
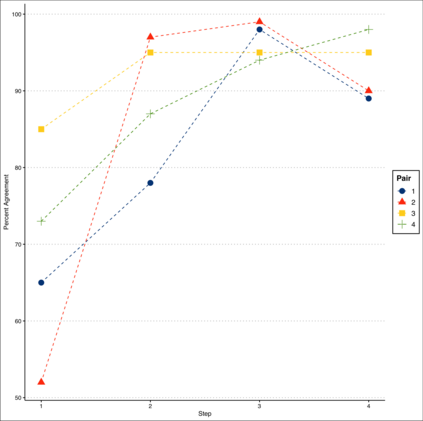
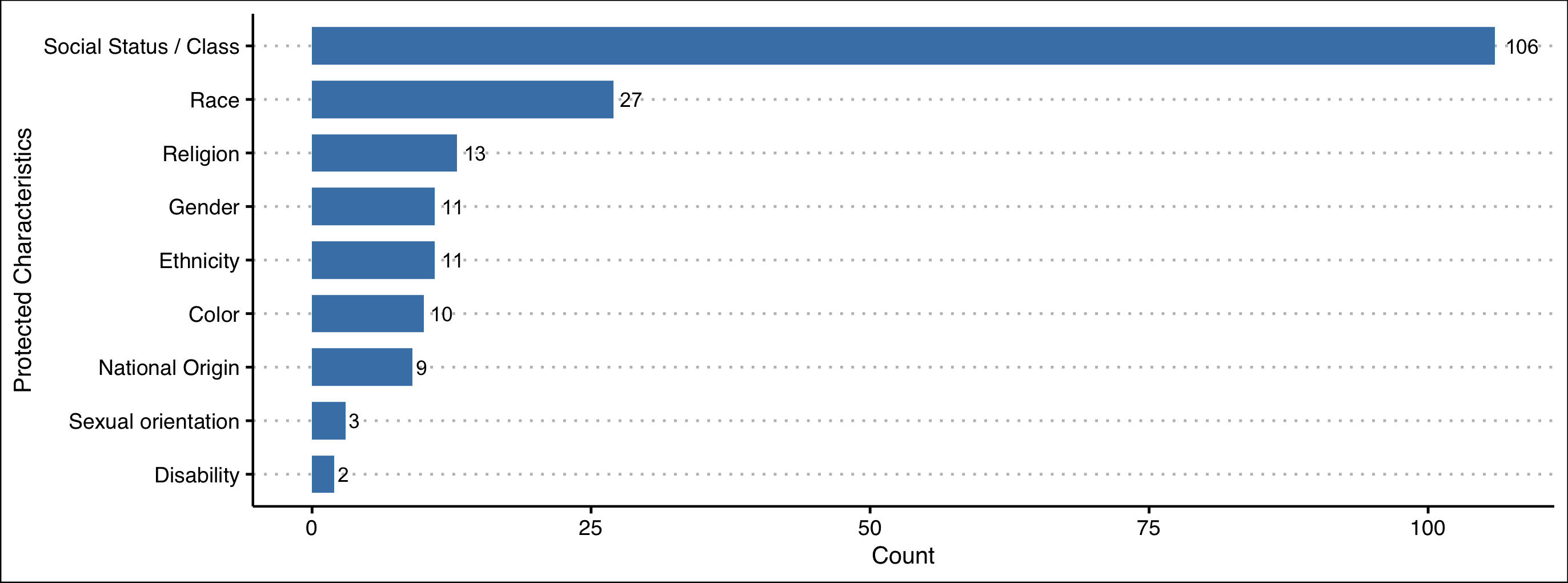
Given Myanmars historical and socio-political context, hate speech spread on social media has escalated into offline unrest and violence. This paper presents findings from our remote study on the automatic detection of hate speech online in Myanmar. We argue that effectively addressing this problem will require community-based approaches that combine the knowledge of context experts with machine learning tools that can analyze the vast amount of data produced. To this end, we develop a systematic process to facilitate this collaboration covering key aspects of data collection, annotation, and model validation strategies. We highlight challenges in this area stemming from small and imbalanced datasets, the need to balance non-glamorous data work and stakeholder priorities, and closed data-sharing practices. Stemming from these findings, we discuss avenues for further work in developing and deploying hate speech detection systems for low-resource languages.
翻译:鉴于缅甸的历史和社会政治背景,社交媒体上的仇恨言论已经升级为离线动荡和暴力事件。本文介绍了我们在缅甸进行的在线自动检测仇恨言论的研究发现。我们认为,有效解决这个问题将需要结合上下文专家的知识和能够分析产生的大量数据的机器学习工具的社区为基础的方法。为此,我们开发了一种系统性方法,以促进这种合作,涵盖数据收集、标注和模型验证策略的关键方面。我们强调了这一领域面临的挑战,包括小型和不平衡的数据集、平衡非光鲜的数据工作和利益相关者的优先考虑,以及封闭的数据共享实践。基于这些发现,我们探讨了进一步研究低资源语言中开发和部署仇恨言论检测系统的途径。